20230717
2023.07.14 - [LG 헬로비전 DX DATA SCHOOL/DATA BASE] - DataBase - 기초
DataBase - 기초
2023-07-14 DataBase kubunetes(해보자!) 1. Docker 설치 Windows는 리눅스를 바로 사용할 수 없어서 WSL 설치를 해주어야 한다. docker : 사이트에서 로그인 Image : 프로그램 Container : 프로그램을 실행한 것 2. 데이
dxdata.tistory.com
DataBase 기초를 본 후 이 글을 보시면 더 도움이 된답니
DATABASE(SQL)
오늘은 DB! 즉, SQL에 대해서 알아보겠습니다!
컴퓨터의 데이터 처리 방식은
-> 프로세서 : CPU,GPU - 메인 메모리 - 보조기억장치
- 메인 메모리 -> 휘발성임. 중간 비용
- 보조 기억 장치(Auxiliary Memory) ->비휘발성, 싼가격/ Flat File(txt, csv)
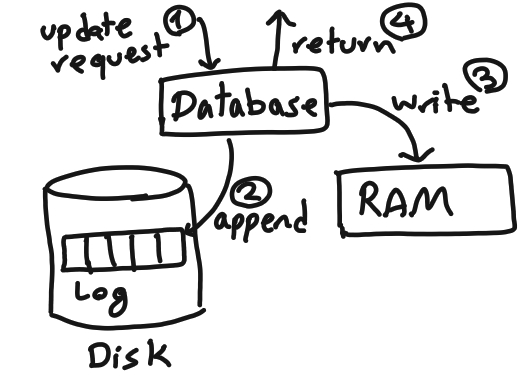
컴퓨터는 저장 용도로 (보조기억장치)Flat file 과 DB(데이터 베이스)가 있다.
이 데이터 베이스에는 Table, SQL, NoSQL(함수 기능) 등이 있다.
데이터 베이스의 쓰임은 포멧시 데이터의 손실을 막기 위해, 컴퓨터와 네트워크로 연결된 저장장소이다.
분산 파일 시스템(DFS, Distributed File System)
처리 -> Hadoop
Hadoop Echo -> 다른 데이터 베이스에 분산하여 데이터 처리
-> 요즘은 클라우드가 위의 기능을 거의 제공해줌.
In Memory DB : 속도가 빠르나, 비용이 비쌈.
(Redis)
프로그래밍을 통한 DB - ORM
flask : 자유도가 높으나 기능이 적음.
django : ORM을 내장하고 있음
MYSQL 설치(sys)
데이터베이스 접속 도구(Dbeaver) <--> SQL ->Data Store 생성
Application 개발 <--> SQL -> Data Store 생성
port 3306은 변하지 않음.
Driver : Application 과 Database 의 인터페이스
정보 : 데이터베이스 종류
URL
Account(ID)
Password(PW)
oracle (root)
DDL (Definition) : Create, Alter, DROR (설계)
DML (Manipulation) :
- (수정)Insert, Update, Delete
- Select(조회) -> DQL (개발자나 사용자)
조회와 수정을 구분하는 것을 CQRS
DCL (Control)
- Grant(권한 부여), Revoke(권한 취소) : 관리
- Commit, Rollback : 개발 TCL
접속도구에 괄호치지마라!
정말로 DB에 대한 기본 내용을 시작해보겠습니다.
1. Docker에서 MYSQL실행
- 이미지 다운로드 및 실행
docker run --name mysql -dit -e MYSQL_ROOT_PASSWORD=wnddkd -e MYSQL_DATABASE=adam -e MYSQL_USER=adam -e MYSQL_PASSWORD=wnddkd -p 3306:3306 mysql --character-set-server=utf8mb4 --collation-server=utf8mb4_unicode_ci --default-authentication-plugin=mysql_native_password
밑줄 친 곳을 변경하면 됩니다.
2.Dbeaver에서 MYSQL 연결하기
파일 - 새로만들기 를 선택하고 DBeaver 탭에서 데이터베이스 연결을 선택하고 MySQL을 선택
접속 정보 작성
- Server Host : 데이터베이스가 위치한 컴퓨터의 IP - 자기 컴퓨터는 localhost
- Port 번호 설정 : 기본은 3306
- Database : 접속할 데이터베이스 이름
- Username : 아이디
- Password : 아이디에 해당하는 비밀번호
만들어진 Connection을 선택하고
docker run --name svng -dit -e MYSQL_ROOT_PASSWORD=252585 -e MYSQL_DATABASE=svng -e MYSQL_USER=svng -e MYSQL_PASSWORD=252585 -p 3306:3306 mysql --character-set-server=utf8mb4 --collation-server=utf8mb4_unicode_ci --default-authentication-plugin=mysql_native_password
3. DBeaver에서 명령 수행
Control + Enter : 커서 위치의 하나의 명령어 실행
마우스 오른쪽[SQL문 ]
4. 데이터베이스 관련 명령
- 데이터베이스 목록 보기
- show database;
- 데이터 베이스 생성
- create database 이름;
- 데이터 베이스 삭제
- drop database 이름;
- 데이터 베이스 사용
- use 데이터베이스 이름;
- 테이블 목록보기
- show tables;
MySQL 작업단위
Database > 테이블
오라클의 경우는 SID(Service Name) > User > 테이블
CREATE TABLE tCity
(
name CHAR(10) PRIMARY KEY,
area INT NULL ,
popu INT NULL ,
metro CHAR(1) NOT NULL,
region CHAR(6) NOT NULL
);
INSERT INTO tCity VALUES ('서울',605,974,'y','경기');
INSERT INTO tCity VALUES ('부산',765,342,'y','경상');
INSERT INTO tCity VALUES ('오산',42,21,'n','경기');
INSERT INTO tCity VALUES ('청주',940,83,'n','충청');
INSERT INTO tCity VALUES ('전주',205,65,'n','전라');
INSERT INTO tCity VALUES ('순천',910,27,'n','전라');
INSERT INTO tCity VALUES ('춘천',1116,27,'n','강원');
INSERT INTO tCity VALUES ('홍천',1819,7,'n','강원');
SELECT * FROM tCity;
CREATE TABLE tStaff
(
name CHAR (15) PRIMARY KEY,
depart CHAR (10) NOT NULL,
gender CHAR(3) NOT NULL,
joindate DATE NOT NULL,
grade CHAR(10) NOT NULL,
salary INT NOT NULL,
score DECIMAL(5,2) NULL
);
INSERT INTO tStaff VALUES ('김유신','총무부','남','2000-2-3','이사',420,88.8);
INSERT INTO tStaff VALUES ('유관순','영업부','여','2009-3-1','과장',380,NULL);
INSERT INTO tStaff VALUES ('안중근','인사과','남','2012-5-5','대리',256,76.5);
INSERT INTO tStaff VALUES ('윤봉길','영업부','남','2015-8-15','과장',350,71.25);
INSERT INTO tStaff VALUES ('강감찬','영업부','남','2018-10-9','사원',320,56.0);
INSERT INTO tStaff VALUES ('정몽주','총무부','남','2010-9-16','대리',370,89.5);
INSERT INTO tStaff VALUES ('허난설헌','인사과','여','2020-1-5','사원',285,44.5);
INSERT INTO tStaff VALUES ('신사임당','영업부','여','2013-6-19','부장',400,92.0);
INSERT INTO tStaff VALUES ('성삼문','영업부','남','2014-6-8','대리',285,87.75);
INSERT INTO tStaff VALUES ('논개','인사과','여','2010-9-16','대리',340,46.2);
INSERT INTO tStaff VALUES ('황진이','인사과','여','2012-5-5','사원',275,52.5);
INSERT INTO tStaff VALUES ('이율곡','총무부','남','2016-3-8','과장',385,65.4);
INSERT INTO tStaff VALUES ('이사부','총무부','남','2000-2-3','대리',375,50);
INSERT INTO tStaff VALUES ('안창호','영업부','남','2015-8-15','사원',370,74.2);
INSERT INTO tStaff VALUES ('을지문덕','영업부','남','2019-6-29','사원',330,NULL);
INSERT INTO tStaff VALUES ('정약용','총무부','남','2020-3-14','과장',380,69.8);
INSERT INTO tStaff VALUES ('홍길동','인사과','남','2019-8-8','차장',380,77.7);
INSERT INTO tStaff VALUES ('대조영','총무부','남','2020-7-7','차장',290,49.9);
INSERT INTO tStaff VALUES ('장보고','인사과','남','2005-4-1','부장',440,58.3);
INSERT INTO tStaff VALUES ('선덕여왕','인사과','여','2017-8-3','사원',315,45.1);
SELECT * FROM tStaff;
DESC tStaff;
DESC tCity;
CREATE TABLE DEPT(
DEPTNO INT(2),
DNAME VARCHAR(14) ,
LOC VARCHAR(13),
CONSTRAINT PK_DEPT PRIMARY KEY(DEPTNO)
);
CREATE TABLE EMP(
EMPNO INT(4),
ENAME VARCHAR(10),
JOB VARCHAR(9),
MGR INT(4),
HIREDATE DATE,
SAL FLOAT(7,2),
COMM FLOAT(7,2),
DEPTNO INT(2),
CONSTRAINT PK_EMP PRIMARY KEY(EMPNO),
CONSTRAINT FK_DEPTNO FOREIGN KEY(DEPTNO) REFERENCES DEPT(DEPTNO)
);
INSERT INTO DEPT VALUES(10,'ACCOUNTING','NEW YORK');
INSERT INTO DEPT VALUES (20,'RESEARCH','DALLAS');
INSERT INTO DEPT VALUES(30,'SALES','CHICAGO');
INSERT INTO DEPT VALUES(40,'OPERATIONS','BOSTON');
INSERT INTO EMP VALUES
(7369,'SMITH','CLERK',7902,'1980-12-17',800,NULL,20);
INSERT INTO EMP VALUES
(7499,'ALLEN','SALESMAN',7698,'1981-2-20',1600,300,30);
INSERT INTO EMP VALUES
(7521,'WARD','SALESMAN',7698,'1981-2-22',1250,500,30);
INSERT INTO EMP VALUES
(7566,'JONES','MANAGER',7839,'1981-4-2',2975,NULL,20);
INSERT INTO EMP VALUES
(7654,'MARTIN','SALESMAN',7698,'1981-9-28',1250,1400,30);
INSERT INTO EMP VALUES
(7698,'BLAKE','MANAGER',7839,'1981-5-1',2850,NULL,30);
INSERT INTO EMP VALUES
(7782,'CLARK','MANAGER',7839,'1981-6-9',2450,NULL,10);
INSERT INTO EMP VALUES
(7788,'SCOTT','ANALYST',7566,'1987-7-13',3000,NULL,20);
INSERT INTO EMP VALUES
(7839,'KING','PRESIDENT',NULL,'1981-11-17',5000,NULL,10);
INSERT INTO EMP VALUES
(7844,'TURNER','SALESMAN',7698,'1981-9-8',1500,0,30);
INSERT INTO EMP VALUES
(7876,'ADAMS','CLERK',7788,'1987-7-13',1100,NULL,20);
INSERT INTO EMP VALUES
(7900,'JAMES','CLERK',7698,'1981-12-3',950,NULL,30);
INSERT INTO EMP VALUES
(7902,'FORD','ANALYST',7566,'1981-12-3',3000,NULL,20);
INSERT INTO EMP VALUES
(7934,'MILLER','CLERK',7782,'1982-1-23',1300,NULL,10);
CREATE TABLE SALGRADE
( GRADE INT,
LOSAL INT,
HISAL INT );
INSERT INTO SALGRADE VALUES (1,700,1200);
INSERT INTO SALGRADE VALUES (2,1201,1400);
INSERT INTO SALGRADE VALUES (3,1401,2000);
INSERT INTO SALGRADE VALUES (4,2001,3000);
INSERT INTO SALGRADE VALUES (5,3001,9999);
COMMIT;
SELECT * FROM DEPT;
SELECT * FROM EMP;
SELECT * FROM SALGRADE;
--회원테이블
create table usertbl(
userid char(15) not null primary key,
name varchar(20) not null,
birthyear int not null,
addr char(100),
mobile char(11),
mdate date)ENGINE=MyISAM AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
--구매테이블
create table buytbl(
num int auto_increment primary key,
userid char(8) not null,
productname char(10),
groupname char(10),
price int not null,
amount int not null,
foreign key (userid) references usertbl(userid) on delete cascade)ENGINE=MyISAM AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
--데이터 삽입
insert into usertbl values('kty', '김태연',1989,'전주','01011111111', '1989-3-9');
insert into usertbl values('bsj', '배수지',1994,'광주','01022222222', '1994-10-10');
insert into usertbl values('ksh', '김설현',1995,'부천','01033333333', '1995-1-3');
insert into usertbl values('bjh', '배주현',1991,'대구','01044444444', '1991-3-29');
insert into usertbl values('ghr', '구하라',1991,'광주','01055555555', '1991-1-13');
insert into usertbl values('san', '산다라박',1984,'부산','01066666666', '1984-11-12');
insert into usertbl values('jsm', '전소미',2001,'캐나다','01077777777', '2001-3-9');
insert into usertbl values('lhl', '이효리',1979,'서울','01088888888', '1979-5-10');
insert into usertbl values('iyou', '아이유',1993,'서울','01099999999', '1993-5-19');
insert into usertbl values('ailee', '에일리',1989,'미국','01000000000', '1989-5-30');
commit;
insert into buytbl values(null, 'kty', '운동화', '잡화', 30, 2);
insert into buytbl values(null, 'kty', '노트북', '전자', 1000, 1);
insert into buytbl values(null, 'jsm', '운동화', '잡화', 30, 1);
insert into buytbl values(null, 'lhl', '모니터', '전자', 200, 1);
insert into buytbl values(null, 'bsj', '모니터', '전자', 200, 1);
insert into buytbl values(null, 'kty', '청바지', '잡화', 100, 1);
insert into buytbl values(null, 'lhl', '책', '서적', 15, 2);
insert into buytbl values(null, 'iyou', '책', '서적', 15, 7);
insert into buytbl values(null, 'iyou', '컴퓨터', '전자', 500, 1);
insert into buytbl values(null, 'bsj', '노트북', '전자', 1000, 1);
insert into buytbl values(null, 'bjh', '메모리', '전자', 50, 4);
insert into buytbl values(null, 'ailee', '운동화', '잡화', 30, 2);
insert into buytbl values(null, 'ghr', '운동화', '잡화', 30, 1);
commit;
위와 같은 코드로 table을 생성하였습니다.
commit;
- 명령문을 선택하고 마우스 오른쪽을 눌러서 [SQL 스크립트 실행]을 선택
- 스크립트 실행 중 오류가 발생하면 오류를 수정하고 그 다음부터 블럭을 잡고 다시 명령을 수행
- 샘플 데이터 확인 :
select *
FROM tCity;
select *
FROM tStaff;
Select *
from DEPT;
select *
from EMP;
select *
from SALGRADE;
SELECT *
FROM usertbl;
SELECT *
FROM buytbl;테이블 구조
테이블 구조 확인 명령 : DESC 테이블 이르미
오라클에서는 sqlplus로 접속해을 떄만 가능
EMP 테이블 - 사원 테이블
- EMPNO - 사원번호, 정수 4자리, Primary Key(Not Null 이고 Unique 하고 테이블에 1개만 존재)
- ENAME - 이름, 문자
- JOB - 직무, 문자
- MGR - 관리자 사원 번호(정수 4자리)
- HIREDATE - 입사일, DATE
- SQL - 급여, 실수이고 소수 2자리
- COMM - 상여금, 실수이고 소수 2자리(NULL 포함)
- DEPTNO - 부서번호, 정수 2자리이고 DEPT 테이블의 DEPTNO를 참조(Foreign Key)
- DEPT 테이블 - 부서 테이블
- DEPTNO: 부서 번호 - 정수 2자리 이고 기본키
- DNAME: 부서 이름 - 문자
- LOC: 위치 - 문자
- GRADE: 호봉 - 숫자이고 기본키
- LOSAL: 최저급여 - 숫자
- HISAL: 최대급여 - 숫자
- NAME: 도시이름 - 문자열이고 기본키
- AREA: 면적 - 정수
- POPU: 인구수 - 정수
- METRO: 대도시 여부 - 문자
- REGION: 도 – 문자
- NAME: 이름 - 문자열이고 기본키
- DEPART: 부서 이름 - 문자열
- GENDER: 성별 - 문자열
- JOINDATE: 입사일 - 날짜
- GRADE: 직무 - 문자열
- SALARY: 급여 - 정수
- SCORE: 고과 점수 - 실수이고 소수 2자리
5. SQL 작성 방법
- 예약어는 대소문자 구분을 하지 않음
- 하나의 명령문 끝은;
명령문의 끝은 ; 이지만 접속 도구를 사용하거나 응용 프로그램을 직접 작성할 때는 ;을 생략 가능
프로그래밍 언어에서는 ; 이 하나의 명령문 끝을 의미하기 때문에 ;을 포함하면 에러가 발생
SQL 종류
DQL(SELECT): 조회
DDL : 데이터 구조 관련 명령 - CREATE, ALTER, DROP, TRUNCATE, RENAME
DML : 데이터 조작 관련 명령 - INSERT, UPDATE, DELETE
TCL : 트랜잭션 조작 명령, DML과 관련 - COMMIT, ROLLBACK, SAVEPOINT
DCL : 데이터 제어 명령 - GRANT, REVOKE 등의 명령
6.SELECT
6.1) 기본구조
- SELECT : 5번, 조회할 열 - 열을 분할 (세로로 쪼개기), 필수
- FROM : 1번, 조회할 테이블 이름 나열, 필수
- WHERE : 2번, 검색 조건 - 행을 분할
- GROUP BY : 3번, 그룹화
- HAVING : 4번, 그룹화 한 이후의 조건
- ORDER BY : 6번 순으로 실행, 정렬 조건
- MySQL(Maria DB에도 존재) 마지막에 LIMIT을 사용하는 것이 가능
순서가 다르게 실행되어, 비절차적이라고 함.
튜닝시, 선 순위 부터 수정할 수 있도록 하는 것이 좋다.
6.2) 테이블의 모든 데이터 조회
SELECT *
FROM 테이블 이름;
6.3) 특정 컬럼의 데이터만 조회
SELECT 컬럼 이름 나열(, 로 구분하면서 나열)
FROM 테이블 이름;
- MySQL의 경우는 테이블 이름은 대소문자를 구분하고 컬럼 이름은 대소문자를 구분하지 않음
- Oracle은 테이블 이름 과 컬럼 이름 모두 대소문자를 구분하지 않음
- 하나의 절을 한 줄씩 쓰는 걸 권장, 두줄의 내용을 한줄에 써도 상관은 없음
6.4) 컬럼 이름에 별명 사용
- 컬럼 이름 다음에 AS 를 추가하고 문자열을 삽입하면 컬럼 이름에 별명이 부여되서 출력 시, 컬럼 이름 대신에 별명이 출력
- 별명에 영문 대문자가 있거나 공백이 있으면 " "로 감싸줘야 함.
- AS는 생략이 가능
6.5) 컬럼의 연산식 출력하는 것이 가능
- +,-,*,/ 를 이용해서 컬럼에 연산을 수행한 후 출력 가능
- 컬럼 이름은 연산식이 되기 때문에 별명을 이용해서 출력함.
- 실제 컬럼이 만들어지는 것이 아니고 내부적으로 연산을 수행해서 출력만 하는 것
- SELECT 절에 단순 연산식 가능한데 MySQL에서는 이 경우에 FROM을 생략하는 것이 가능
6.6) 컬럼 연결 조회
- CONCAT 함수 이용
이 함수의 역할은 2개의 데이터를 하나로 묶어주는 역할을 수행하는 함수
-- tCity 테이블에서 name과 area 컬럼을 조회
SELECT name, area
FROM tCity;
-- tCity 테이블에서 name과 area 컬럼을 조회
SELECT CONCAT(name, ' : ',area)
FROM tCity;
6.7) DISTINCT
- SELECT 바로 뒤에 한번만 기재해서 컬럼의 중복 값을 제거하고 출력하는 예약어
- DISTINCT 뒤에 컬럼 이름이 1개인 경우는 그 컬럼의 값이 동일한 경우만 제거하고 2개 이상이 나오는 경우는 모든 컬럼의 값이 동일해야만 제거
- DISTINCT의 경우는 GROUP BY를 이용해서도 작성이 가능(동일한 결과)
- Cardinality : 중복 제거된 종류 수, degree : 열의 개수
6.8) Sort(정렬)
정렬의 종류
- ASCENDING(오름차순) : 작은 것에서 큰 것 순으로 나열, 디폴트 (ASC)
- DESCENDING(내림차순) : 큰 것에서 작은 것 순으로 나열, 지정을 해야 함 (DESC)
정렬을 수행하는 위치에 따라서 내부(메모리 내부) 정렬과 외부(메모리 외부) 정렬로 나누기도 하고 정렬을 할 때 수행하는 알고리즘의 방식에 따라 분류하기도 합니다.
- 오름차순
숫자나 문자, 날짜는 작은 것에서 큰 것 순으로
NULL 값은 제일 나중
- 내림차순
ORDER BY 컬럼이름 [ASC | DESC]
ASC는 생략이 가능함
- 컬럼 이름 대신에 SELECT 절에서 만든 별명 사용 가능하고 인덱스(SELECT 절에서 조회하는 순서인데 첫번째는 1)를 이용해서도 가능
- 연산식으로 정렬하는 것도 가능
- 2개 이상의 정렬 조건을 기재할 수 있는데 이 경우는 앞의 정렬 조건이 같은 값일 때, 뒤의 조건이 적용
- SELECT를 할 때 2개 이상의 행이 리턴되면 ORDER BY를 해주는 것이 좋다.
-> 하지 않아도 에러는 아닌데, 데이터가 어떤 순서로 출력될지 알 수 없기 때문이다.
ORACLE의 경우는 입력 순서를 기억하여 그대로 리턴을 하고 SQL server와 MySQL(Maria DB) 는 Primary Key 순서대로 리턴을 합니다.
-- tCity 테이블에서 모든 데이터를 조회하는 데 popu의 오름차순으로 조회
SELECT *
FROM tCity
ORDER BY popu; -- ASC;
-- tCity 테이블에서 모든 데이터를 조회하는 데 popu의 내름차순으로 조회
SELECT *
FROM tCity
ORDER BY popu DESC;
-- tCity 테이블에서 region, name, area, popu를 조회하는데
-- region의 오름차순으로 조회
SELECT region, name, area, popu
FROM tCity
ORDER BY region;
-- Primary Key 순으로, 1번째가 같다면 2번째에서 앞, 뒤를 판별
-- tCity 테이블에서 region, name, area, popu를 조회하는데
-- region의 오름차순으로 조회하되 동일한 값이면 AREA 가 큰 것이 먼저
SELECT region, name, area, popu
FROM tCity
ORDER BY region, area DESC;
-- 정렬을 할 때는 SELECT 절의 인덱스와 별명을 이용하는 것이 가능
SELECT region AS 지역, name AS 이름, area, popu
FROM tCity
ORDER BY 지역, 3 DESC;
-- tStaff 테이블의 모든 데이터를 조회하되, salary 가 작은 사람부터 그리고 salary가 동일하면 score가 높은 사람부터 조회
SELECT *
FROM tStaff
ORDER BY salary, score DESC;
6.9) WHERE
- 테이블의 데이터를 SELECTION(행을 선택하는) 하는 절
- SELECT 절은 PROJECTION(열을 선택하는) 하는 절
- 조건을 기재해서 조건에 맞는 데이터를 골라내는 것.
- 기본 연산자
- >
- >=
- <
- <=
- =
!=, < > , ^= : 다르다
NOT 컬럼이름 연산자 값
- 값을 표기할 때는 숫자는 그냥 표기하면 되지만 문자열 과 날짜는 ' '안에 기재
- MySQL 이나 Maria DB는 " "안에 기재해도 되며 대소문자 구분을 하지 않음. 저장할 때는 구분
대소문자를 구분해서 조회하는 방법
테이블 만들기 전 :
- 테이블을 만들 때 VARCHAR 대신에 VARBINARY를 이용
- 테이블을 만들 때 VARCHAR를 이용할 때 뒤에 BINARY를 추가해서 생성
테이블 만든 후 :
- 테이블이 이미 만들어진 경우는 조회를 할 때 COLLATE utf8_bin 을 추가
- 칼럼 이름을 BINARY로 감싸서 조회
-- tCity 테이블에서 name 이 서울인 데이터를 조회
SELECT *
FROM tCity
WHERE name = "서울";
-- tCity 테이블에서 metro 가 y인 테이블을 조회
SELECT *
FROM tCity
WHERE metro = 'y'; -- 'Y'로 작성하여도 가능
-- 대소문자를 구분해서 데이터를 조회
SELECT *
FROM tCity
WHERE BINARY(metro) = 'y';
-- 이땐 'Y'를 넣으면, ㅔ이블 내에 'Y'로 된 값이 없어서 조회가 안됨.CHAR 과 VARCHAR의 차이를 아는 것이 중요하다.
CHAR는 말 그대로 고정형입니다. ex) CHAR(8)로 선언 시 글자를 한 개를 넣든 두 개를 넣든 8바이트의 공간을 차지합니다. VARCHAR는 반대로 가변형 문자열이기 때문에 데이터의 길이에 따라서 가변적으로 길이가 정해집니다.
NULL 값의 저장은, 메모리 내에, NULL 여부가 있는 부분 없는 부분으로 나뉘어지고, 그 여부가 따로 0/1로 나뉜다.
Kotlin, Java가 NULL 여부와 함께 저장된다.
- 논리 연산자
NOT : 결과를 반대로
AND : 그리고
OR : 또는
AND 가 OR 보다 우선 순위가 높음
-- tCity 테이블에서 popu 가 100 이상이고 area 가 700 이상인 데이터 조회
-- AND 나 OR 에서 조건의 순서는 결과에 영향 X, 과정에 영향을 미칠 뿐
-- AND 나 OR를 이용한 쿼리를 만들 때는 순서를 잘 확인해야 합니다.
SELECT popu
FROM tCity
WHERE popu >= 100;
SELECT popu
FROM tCity
WHERE area >= 700;
-- 100일 때 더 적은 값이 나오므로, 100을 우선 시한다.
SELECT *
FROM tCity
WHERE popu >= 100 AND area >= 700; #2개의 데이터를 골라내어, 뒤 조건을 확인한다.
SELECT *
FROM tCity
WHERE area >= 700 AND popu >= 100; #5개의 데이터를 골라내어, 뒤 조건을 확인한다.
-- tStaff 테이블에서 salary가 300 미만이거나 score가 60 이상인 직원의 모든
-- 컬럼을 조회
SELECT salary
FROM tStaff
WHERE salary < 300; -- 5개 데이터
SELECT score
FROM tStaff
WHERE score >= 60; -- 10개 데이터
-- or는 아닌게 더 적을 수록 좋다.
SELECT *
FROM tStaff
WHERE score >= 60 OR salary < 300;- and 는 앞의 조건에서 true 의 결과가 적을 수록 좋고, or 연산은 앞의 조건에서 true가 많을 수록 좋다.
LIKE
부분 일치하는 문자열(날짜)를 찾을 때 사용
와일드 카드 문자
- % : 글자 수와 상관이 없음.
- _ : 1글자
- %A : AAA, BBA, A, BA도 가능, A로 끝나는 글자수 상관없는 글자.
- _A : BA는 가능하고 AAA, BBA, A 는 안됨.
- [글자 나열] : 나열 된 글자 중 하나
- [^글자 나열] : 나열 된 글자가 아닌 것
LIKE 가 아닌 : NOT LIKE
와일드카드 문자를 검색하고자 하는 경우는 ESCAPE를 이용
-- tCity 테이블에서 name에 천이 포함된 모든 데이터를 조회
-- LIKE의 활용
SELECT *
FROM tCity
WHERE name LIKE "%천%"; -- 시작 혹은 끝이냐에 따라서, %를 넣거나 안넣거나
SELECT *
FROM tCity
WHERE name LIKE "_천"; -- 천으로 끝나는 두글자 문자열
-- EMP 테이블에서 ename 에 L이 2개 포함된 데이터를 조회
SELECT *
FROM EMP
WHERE ENAME LIKE "%L%L%";
-- tStaff 테이블에서 joindate(입사일)가 10월인 사원을 조회
SELECT *
FROM tStaff
WHERE joindate LIKE "%-10%"; -- 혹은 '____10%'
-- sale 에 30% 가 포함된 데이터를 조회
-- 예시 sale LIKE "%30#%%" ESCAPE '#' -- #뒤에 나오는 것은 일반 문자로 취급
BETWEEN
- 데이터 BETWEEN A AND B 형태로 사용하는데 >=A AND <= B 임.
- BETWEEN은 순서를 바꾸면 안되고 앞 쪽은 작은 값이 나와야 한다.
- 데이터베이스에서는 문자열과 날짜도 크기 비교 가능
-- sale 에 30% 가 포함된 데이터를 조회
-- 예시 sale LIKE "%30#%%" ESCAPE '#' -- #뒤에 나오는 것은 일반 문자로 취급
-- tCity 테이블에서 popu 가 50에서 100사이인 데이터를 조회
SELECT *
FROM tCity
WHERE popu >= 50 AND popu <=100;
SELECT *
FROM tCity
WHERE popu BETWEEN 50 AND 100;
-- tStaff 테이블에서 joindate 가 2018년인 데이터를 조회
-- BETWEEN 과 LIKE
SELECT *
FROM tStaff
WHERE joindate BETWEEN '2018-01-01' AND '2018-12-31';
SELECT *
FROM tStaff
WHERE joindate LIKE "2018%";
IN
IN (데이터 나열) 형태로 작성하는데 데이터에 포함된 데이터 조회
NOT IN(데이터 나열) 형태로 작성하면 데이터에 포함되지 않은 데이터 조회
-- tCity 테이블에서 region 이 경상 또는 전라 인 데이터를 조회
SELECT *
FROM tCity
WHERE region = '경상' OR region = '전라'
-- 혹은
SELECT *
FROM tCity
WHERE region IN('경상','전라')
6.10) 행의 개수 제한
- ORACLE 에서는 ROWNUM과 INLINE VIEW 또는 FETCH~OFFSET을 이용하고 MS-SQL Server는 TOP을 이용하는데 MySQL(Maria DB)에서는 SELECT 구문의 마지막에 LIMIT를 이용해서 제한
- LIMIT [건너뛸 개수,] 조회할 개수
건너뛸 개수를 생략하면 0
- LIMIT 조회할 개수 OFFSET 건너뛸 개수 형태로 입력해도 됩니다.
- 이 구문은 TOP-N(ex.유튜브에 알고리즘으로 뜰 영상 수) 이라고도 부르기 때문에 ORDER BY와 같이 사용됩니다.
-- tCity 테이블에서 area가 넓은 3개의 데이터 조회
SELECT *
FROM tCity
ORDER BY area DESC
LIMIT 3; -- top 3개
SELECT *
FROM tCity
ORDER BY area DESC
LIMIT 3, 3; -- top 4~6
SELECT *
FROM tCity
ORDER BY area DESC
LIMIT 6, 3; -- 앞자리는 건너 띌 개수 top 7~9
-- OFFSET 6; 으로 사용해도 됨
-- tStaff 테이블에서 salary가 12위 부터 16위 까지 조회
SELECT *
FROM tStaff
ORDER BY salary DESC
LIMIT 11, 5 -- 5
-- OFFSET 11 건너뛸 개수
6.11) Scala Function
- 데이터 베이스에서의 함수
Maker Fuction 과 User Define Function으로 나눌 수 있음.
- Maker Function의 분류
Scala Function : 행 단위로 연산
- 일반적으로 SELECT 절이나 WHERE 절 또는 ORDER BY에도 사용이 가능
- 수치 함수 :
- ABS : 절대값
- ROUND(데이터, 반올림 할 자릿수를 설정/ 음수를 이용하면 0의 자리 부터 위로)
- TRUNCATE
- CEILING, FLOOR
- MOD : 나머지
- 문자열 함수 :
- ASCII(문자), CHAR(숫자) : 문자와 숫자의 코드 값 변환
- BIT_LENGTH, CHAR_LENGTH, LENGTH : 글자 수와 바이트 수를 반환하는 함수(영문은 글자당 1 바이트, 한글은 글자 당 3 바이트) 리턴
- UPPER, LOWER : 영문 대소문자 변환
- LTRIM, RTRIM : 좌우 공백 제거
- TRIM : 양쪽 공백 제거
- REPLACE(문자열, 원래 문자열, 변경할 문자열) : 문자열 변경
- SUBSTRING(문자열, 시작위치, 자를 개수)
- CONCAT(문자열 나열) : 문자열을 하나로 결합
- 날짜 관련 함수
- 데이터 베이스 에서는 날짜를 숫자로 취급
- 날짜와 날짜 그리고 날짜와 정수 사이 연산이 가능
- 하루를 1로 간주 합니다.
CURRENT_DATE(), CURDATE() : 현재 날짜
CURRENT_TIME(), CURTIME() : 현재 시간
NOW(), LOCALTIME(), LOCALTIMESTAMP(), CURRENT_TIMESTAMP() : 현재 날짜 및 시간
날짜 및 시간 추출 함수
- YEAR, MONTH, DAY, HOUR, MINUTE, SECOND, MICROSECOND
날짜 및 시간 계산 함수
- ADDDATE(날짜, 차이), SUBDATE(날짜, 차이)
- ADDDATE(날짜, 차이), SUBTIME(날짜, 차이)
- DATEDIFF(날짜1, 날짜2)
특정 날짜 생성
- STR_TO_DATE(날짜 문자열, 서식)
날짜에 특정 기간을 추가
- 날짜 + INTERVAL 값 단위
SQL 파일을 DBEAVER에서 실행하기
Windows 에서 DBeaver dnlcl - C:\Users\USER\AppData\Local\Dbeaver
끝!
물론 오늘 치만 끝난거지 배움에는 끝이 없습니다.
오늘도 고생하신 모든 여러분 존경하고 화이팅 하시길 바랍니다.
내일을 위해서 오늘 하루의 마무리도 중요하다는 점 항상 상기하시고
다들 내일 더 빛날 나를 위해 오늘 좀 더 고생합시다!
'LG 헬로비전 DX DATA SCHOOL > DATA BASE' 카테고리의 다른 글
| 파이썬 MySQL 연동 (0) | 2023.07.20 |
|---|---|
| DATA BASE 4 (0) | 2023.07.20 |
| Data Base 3 (0) | 2023.07.19 |
| Data Base 2 (0) | 2023.07.18 |
| DataBase - 기초 (0) | 2023.07.14 |



