2023/08/03
Tableau 입문에 이어 두번째 시간을 시작해 보겠습니다!
2023.08.02 - [LG 헬로비전 DX DATA SCHOOL/Tableau] - Tableau 입문
Tableau 입문
2023-08-02 **Tableau 1. 태블로 사용시 필요할 수 있는 Excel 파일으 공유합니다. 데이터를 분석 및 시각화하는 BI(Business Intelligence) Solution BI는 비지니스를 운영하면 얻은 데이터를 수집, 저장, 분석해서
dxdata.tistory.com
1. Heat Map CHart
1.1) 개요
- 테이블 형식의 데이터를 색상으로 표현할 수 있는 차트
유사한 차트로 Tree Map 은 각 셀의 크기로도 데이터의 차이를 표현 가능
- 차원을 2개를 사용하는데 2개의 차원의 연관성을 파악하거나 상위 차원과 하위 차원 형태로 배치를 세부 항목을 보여주는 형태로 많이 사용
- 수치 나 경향 보다는 색상의 차이가 시각적으로는 효과가 뛰어나기 때문에 값의 차이가 큰 경우 많이 사용합니다.
- 2개의 차원과 하나의 측정 값을 가지고 작성
트리 맵은 2개의 차원과 2개의 측정 값까지 가능
1.2) 월 별 그리고 요일 별 매출액의 합계 파악
- 사용하고자 하는 엑셀파일! 슈퍼 스토어 파일! 위의 파일을 다운로드 해주세
- 사용하고자 하는 시트를 캔버스로 이동 : 주문 시트 이용(from 절)
- 마크 선반에서 유형을 [ 사각형 ] 으로 변경
- 주문 날짜 필드를 행과 열에 배치
- 열 선반에 배치한 주문 날짜를 필드를 클릭하여 불 연속형의 요일을 선택
- 행 선반에 배치한 주문날짜 필드를 클릭해서 불 연속형의 월을 선택

- 출력할 측정 값(매출액)을 마크 선반의 색상에 배치
- 색상의 변화가 작으면 마크 선반의 색상을 클릭해서 색상을 변경
- 정확한 값을 표시하고자 한다면 측정값을(매출액) 마크 선반의 레이블로 드래그
2. 여러 시트 조인
- 태블로에서는 시트 간에 동일한 차원이 존재하는 경우 조인이 가능
동일한 차원이 없더라도 강제로 조인을 할 수 있습니다.
- Union(여러 개의 구조가 같은 시트를 합치는 것) 도 가능
- 기준이 되는 시트를 먼저 배치하고 다른 시트를 배치할 때 시트 위에 배치하면 Union 이고 오른쪽이나 왼쪽에 배치하면 JOIN
- JOIN 시 공통된 컬럼을 알아야 한다.
데이터베이스에서 JOIN을 할 때는 순서도 중요합니다.
실습 - JOIN
시작하기 앞서
연습용 엑셀파일 입니다. 다운로드 받으셔도되고 다른 개인 엑셀 파일로 과정만 따라하셔도 됩니다.
- Car_Order -> Car_Member -> Car_OrderDetail -> Car_Product -> Car_Store Sheet 를 추가\
Car_Order에 Member, OrderDetail, Store를 조인
OrderDetail 에 Product를 연결
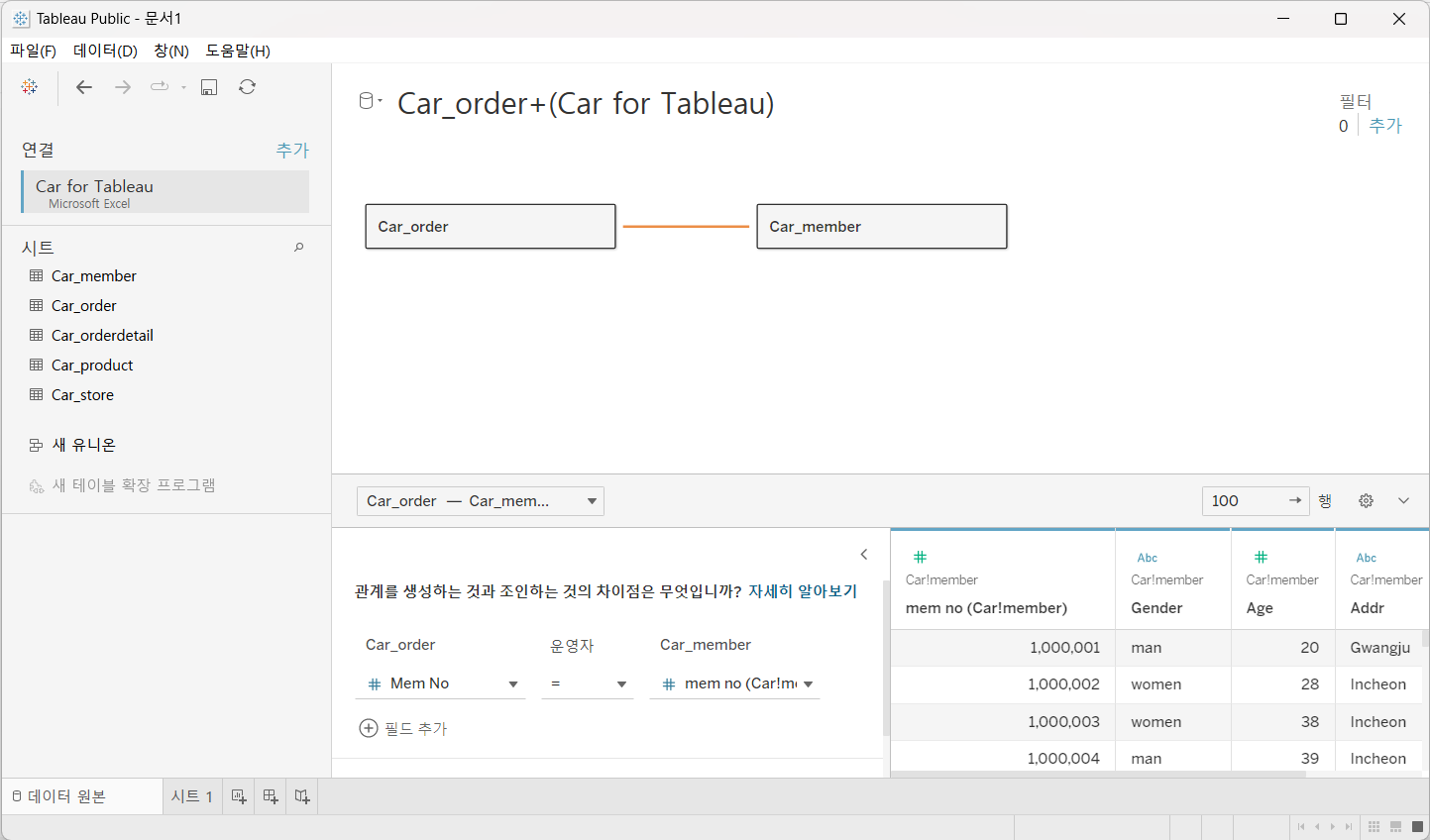
드래그 드롭만 하더라도, mem no라는 공통 컬럼으로 JOIN!
연결할 수 없는걸 연결하면

- Order가 아니라, orderdetail에 연결하면 잘 되는 모습

3. 필터
3.1) 데이터 원본 필터
- 연결된 데이터 원본에 필터를 적용
- 데이터를 불러오는 단계에서 필터링 되기 때문에 대용량 데이터를 불러올 때 활용
- 데이터 원본에서 Type에서 truck을 제외
데이터 원본 화면의 오른쪽 상단의 필터의 추가를 클릭해서 원하는 데이터만 추출
3.2) 워크시트 페이지 및 필터
- 워크 시트 페이지
필터 이동 및 재생을 통해 워크시트 뷰를 동적(애니메이션)으로 보이게 하는 기능
- 실습
Type 별 매출액(존재하지 않는 측정값)을 이용한 막대 그래프 출력
존재하지 않는 측정값은 계산된 필드(파생 속성 - Derived Attribute : 이러한 속성을 자주 사용하는 경우에는 컬럼으로 추가하는 것이 좋다. 대부분의 경우 RDBMS에서 데이터를 가져와서 사용하는데 RDBMS에서는 근본적으로 데이터의 중복이나 계산식으로 나오는 파생 컬럼을 만들지 않습니다.)를 이용해서 생성
매출액은 Price * Quantity([Price] * [Quantity]) 로 생성
행과 열에 Type과 매출액을 설정
Type을 마크에 올리면 색상을 띄울 수 있고, 매출액을 레이블로 설정이 가능함

애니메이션을 위해서 페이지에 Order Date를 드래그해서 설정하고 데이터 형식을 yyyy년 m 월로 변경

- 워크시트 필터
차원 또는 측정값 필드를 이용해서 워크시트 뷰를 필터링하는 기능
필터링해서 출력하는 것이지 데이터를 필터링하는 것이 아님.
- 워크시트 필터 실습
모델별 매출액 막대 차트 생성
행과 열에 Model 과 매출액을 배치
매출액을 마크 카드의 색상과 레이블에 설정
툴 바의 정렬을 이용해서 내림차순으로 설정

- 필터링
Model을 선택하고 필터로 드래그 앤 드롭
일반에서는 특정 한 겂을 포함시키거나 제거가 가능
와일드 카드에서는 특정 문자로 시작하거나 종료되는 그리고 포함한 값과 정확히 일치를 설정할 수 있습니다.
조건에서는 직접 조건을 설정하는데 크다 작다 크거나 같다 작거나 같다 등.
상위에서는 상위 또는 하위에서 몇 개를 추출할 수 있음
필터를 만들 때 측정 값을 설정하게 되면 범위 / 최대 / 최소 / 특수 4 가지 형태로 조건을 설정

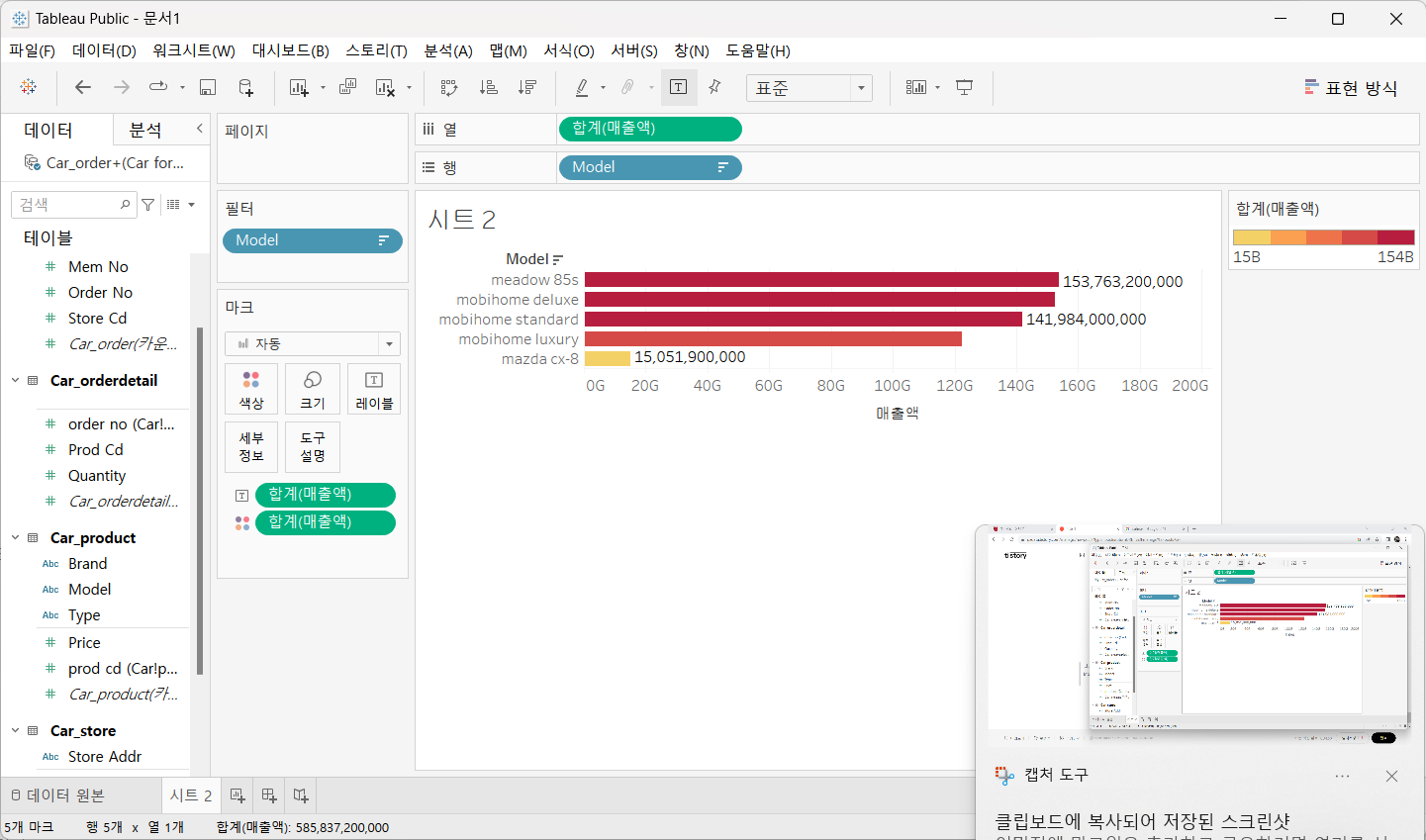
상위 5개의 매출액이 80억을 넘고 m으로 시작하는 값 필터링
4. 필드 변환
- 차원 또는 측정값을 이용해서 시각화에 필요한 새로운 필드로 변환
- 만들기 / 변환 / 변경 등의 작업이 가능
- 차원과 측정값은 변환이 다릅니다.
4.1) 별칭
- 값에 별명을 붙이는 것
- 차원 데이터에서 값 대신에 특별한 문자열이나 값을 사용하는 것
- 문자열이 열거형(특정 값 만으로 구성된 데이터로 범주형이라고도 함 - factor)인 경우
- 숫자로 된 데이터에 문자열을 표시하거나 영문이나 다른 언어로 만들어진 데이터에 한글 별명을 주는 경우가 많습니다.
데이터베이스에서는 기본적으로 열거형을 사용하지 않기 때문에 열거형의 경우 일반 문자열이나 정수로 표현
이런 경우 알아보기가 어렵기 때문에 별칭을 사용
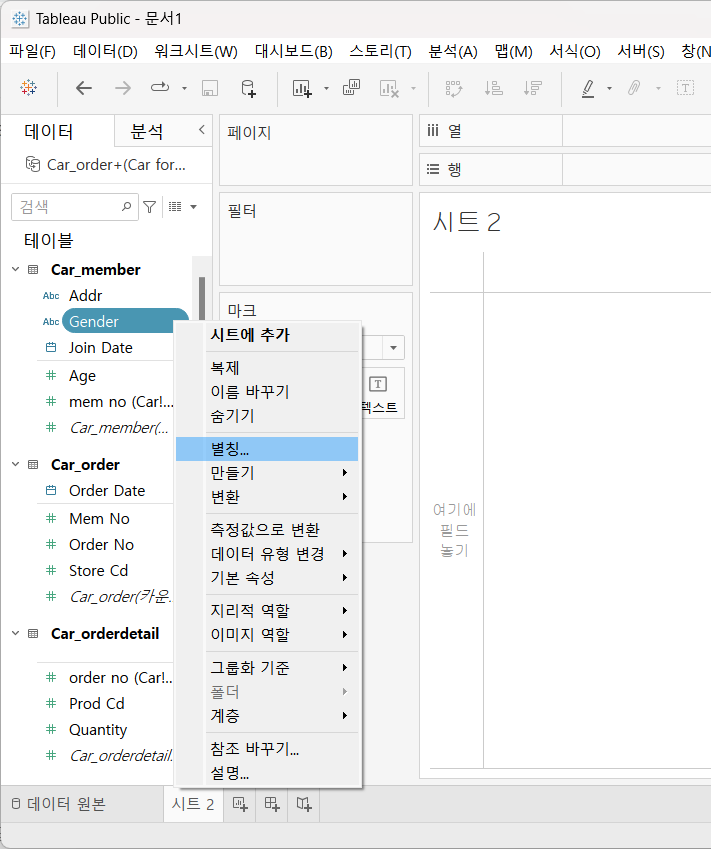
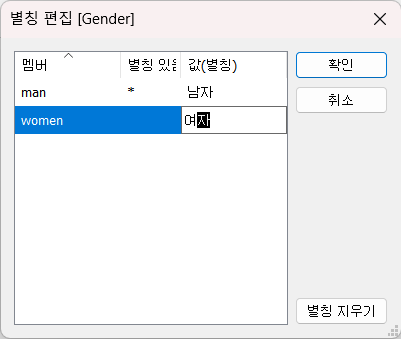
- Gender 필드에 별칭 사용
man -> 남자
woman -> 여자
Gender 필드를 클릭 후 눌러서 변경
확인 시에는 Gender 필드를 행에 올려놓으면 확인 가능
4.2) 계산된 필드
- 함수를 사용해서 필드를 계산
- 사이드 바의 빈 영역에서 마우스 오른쪽을 눌러서 [계산된 필드 만들기] 를 이용해도 되고 사이드 바 상단의 추가 메뉴를 눌러서 생성하는 것이 가능
- 태블로가 제공하는 함수와 IF ~ ELSEIF ~ ELSE END 사용이 가능
- 2개의 계산된 필드 생성
국가 브랜드 : Brand 값이 chevolet 이면 미국, bmw 이면 독일, peugoet이면 프랑스 나머지는 일본
IF [Brand] = 'chevolet' THEN '미국' ELSEIF [Brand] = 'bmw' THEN '독일' ELSEIF [Brand] = 'peugeot' THEN '프랑스' ELSE'일본' END
평균 가격 : Price 필드의 평균
AVG([Price])
4.3) 그룹
- [차원] 이나 [측정값]을 그룹화 할 때 사용하는데 대부분의 경우는 차원을 그룹화하는데 사용
- Brand를 그룹화
[Brand] 를 클릭하여 [만들기] -> [그룹] 클릭하여 그룹 설정
그룹화하고자하는 항목을 선택하고 그룹을 누르고 그룹 명을 입력 (SQL의 GROUP BY 느낌)

4.4) 집합
- 데이터를 미리 선정해두고 사용하는 것
- 동적 집합과 정적 집합이 있는데 동적 집합은 데이터의 값에 따라 변경이 될 수 있는 것으로 단일 차원으로 만들어야하고 정적(고정) 집합은 데이터를 고정시켜서 선택하는 것으로 변경이 안되지만 여러 차원으로 만들 수 있다.
Model 과 매출액을 이용하여 막대 그래프 그리기

동적 집합 만들기
Model 필드 클릭 후 [만들기] - [집합]을 선택하고 이름은 모델(매출액 상위 10)으로 하고 상위 10으로 조건 설정
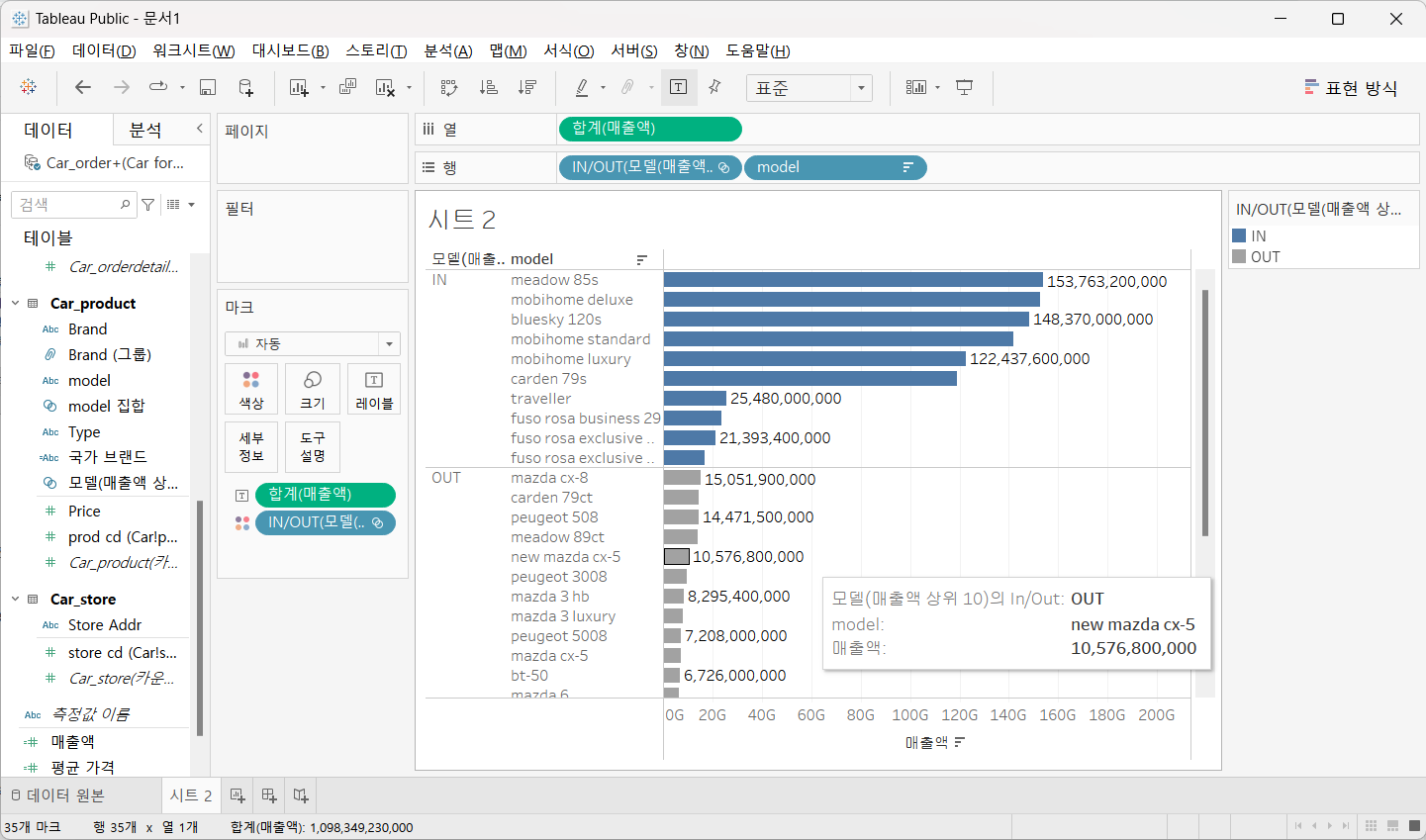
매출액을 행에, 평균 가격을 열에 드래그
Brand 와 Model을 마크 세부정보에 드래그
분산형(Scatter) 차트에서 그룹화하고 싶은 데이터만 드래그해서 선택하고 나오는 메뉴에서 [그룹만들기] 선택하고 그룹 이름을 입력하면 됩니다.

4.5) 구간 차원(Binning)
- 연속형 데이터를 범주(차원, Factor, 열거형 - Enum)형으로 만들고자 할 때 사용
- Age를 10살 간격으로 구간화
Age 를 클릭 후 [만들기] - [구간 차원]을 선택한 후 이름을 입력하고 각 구간의 크기를 설정
만들어진 필드를 행으로 드래그 하면 확인 가능

Age를 마크선반 텍스트에 드래그
Age의 측정값을 평균으로 변경

4.6) 매개변수
- 사용자가 직접 값을 설정하거나 입력해서 뷰를 필터링하기 위한 기능
- 단독으로 사용될 수 없으며 차원이나 측정 값 또는 계산된 필드와 같이 동작
태블로 매개변수를 만들 때는 필드에 포함되지 않음 -> 값만 입력되어 어떤 항목이 속하는지 알기 힘듬.
- 생성을 할 때는 사이드 바의 빈영역에서 마우스 오른쪽을 눌러서 만들 수 있고 사이드 바 상단의 추가 메뉴를 클릭해서 생성 가능
- 날짜를 갖는 매개변수 2개를 생성
[시작일], [종료일]
- 만든 매개변수 사용
행에 [Order Date] 필드를 배치하고 속성을 불 연속형 월로 변경
매출액을 마크 카드의 텍스트에 배치
매개변수를 활용하기 위한 계산된 필드 생성 - 매개 변수(Order Date)
IF [Order Date] >= [시작일] AND [Order Date] <= [종료일]
THEN 'Y' ELSE 'N' END행에 [매개변수 Order Date] 필드를 드래그
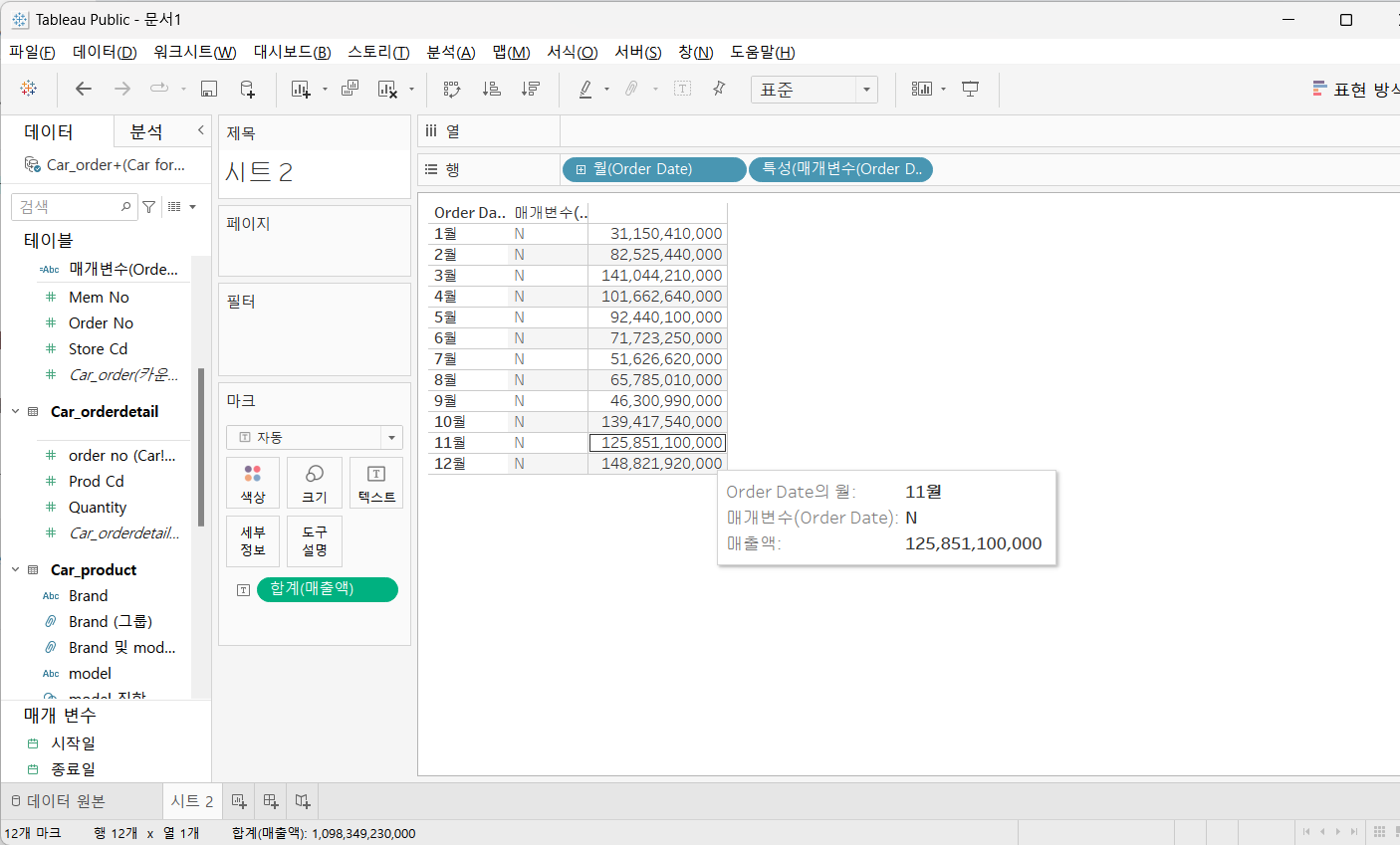
매개변수를 화면에 표시 - 매개변수를 선택하고 표시를 선택

계산된 필드(매개변수(Order Date))를 필터로 드래그 하고 체크 박스의 'Y'에 선택
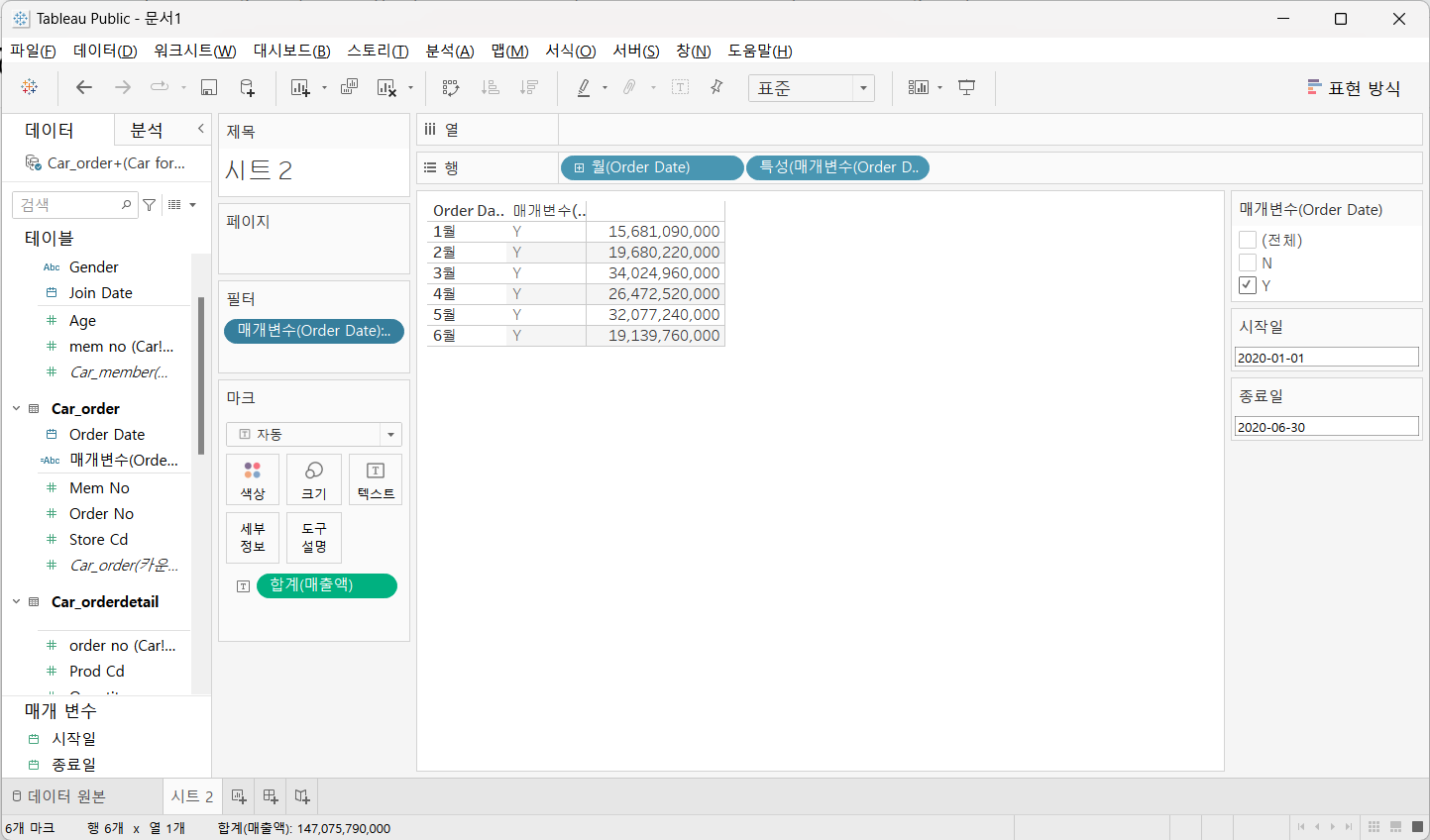
- 매개 변수를 적절히 활용하면 동적으로 뷰를 변경하면서 데이터를 확인하는 것이 가능
4.7) 변환
- 차원 필드 값을 여러 필드로 나눌 때 사용
분할 : 태블로가 자동으로 분할 - 반복되는 패턴이 있는 경우
사용자 지정 분할 : 구분 기호로 직접 분할
- 자동 분할
[Store Addr] 선택 후 [변환] - > [분할] 클릭
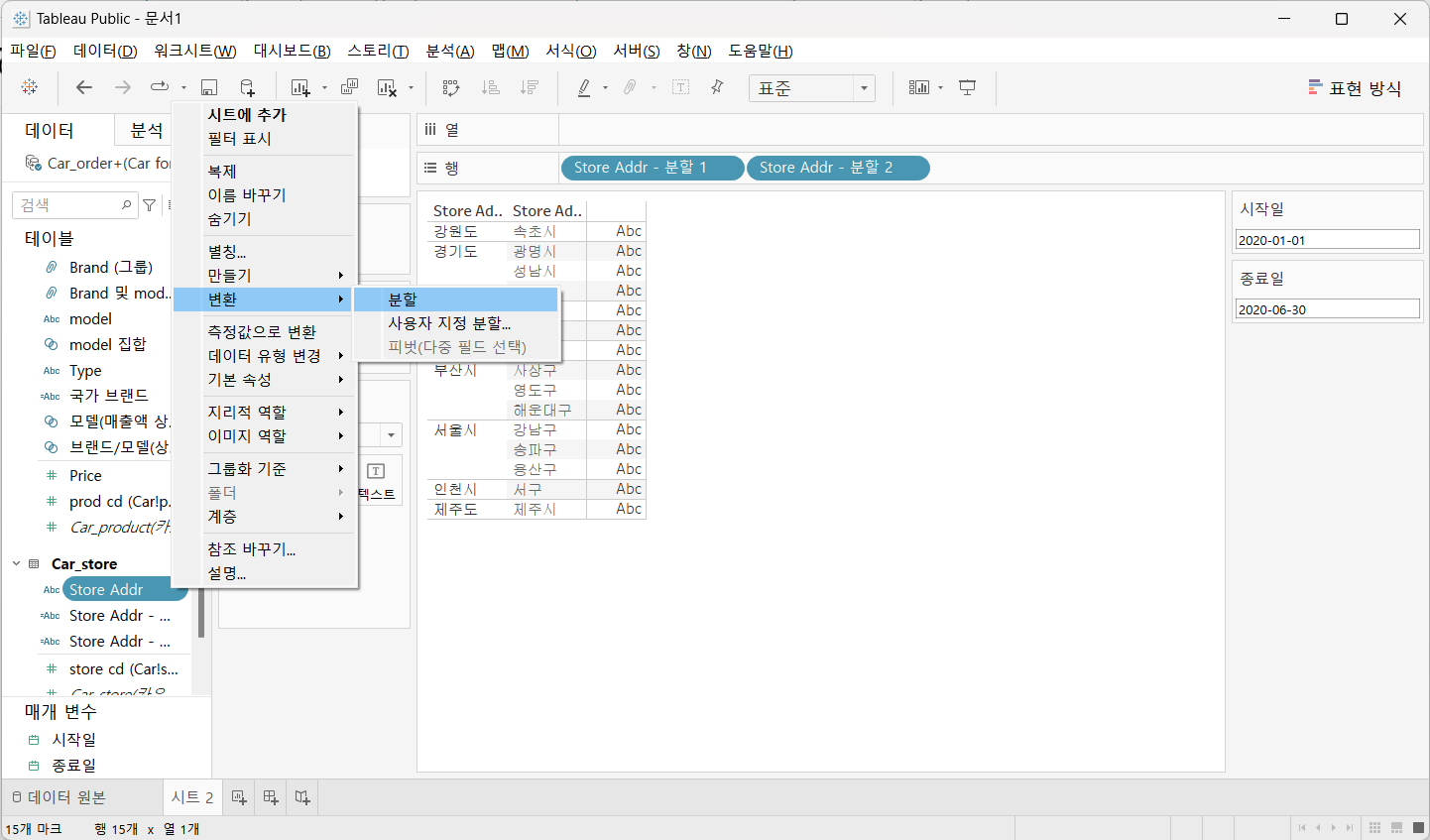
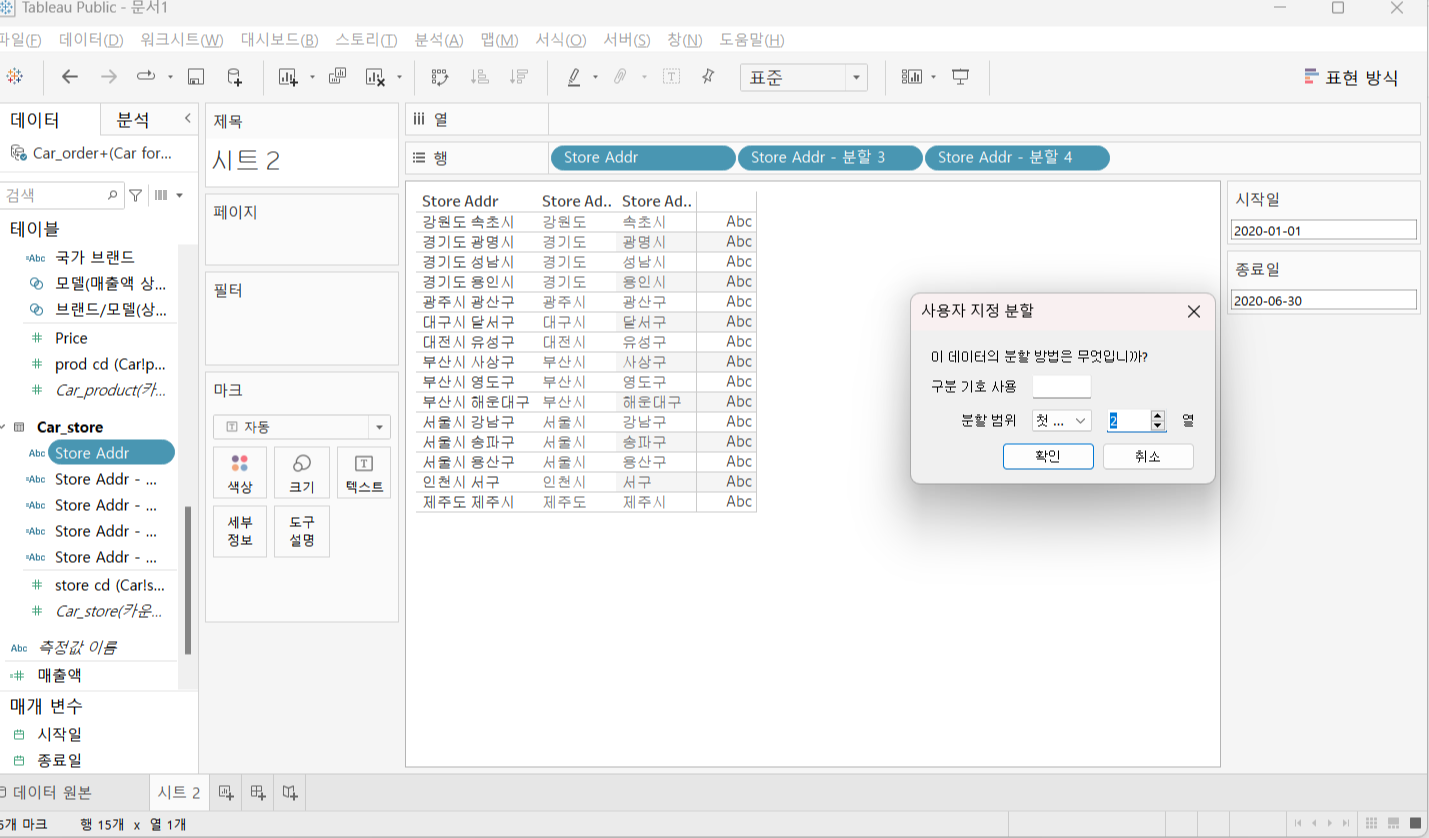
- 직접 분할
[Store Addr] 선택 후 [변환] - > [사용자 지정 분할] 클릭 후 구분 기호를 설정
최대 개수인 2를 설정! (언어 마다 차이가 있음을 인지할 필요)
split 은 기호가 정규 표현식인지 아니면 문자열인지 확인을 하고 1가지로 분할이 가능한지 아니면 여러 가지 설정이 가능한지 그리고 분할할 개수를 설정할 수 있는지 확인
indexOf 나 lastIndexOf 는 시작할 위치를 설정할 수 있는지 확인!
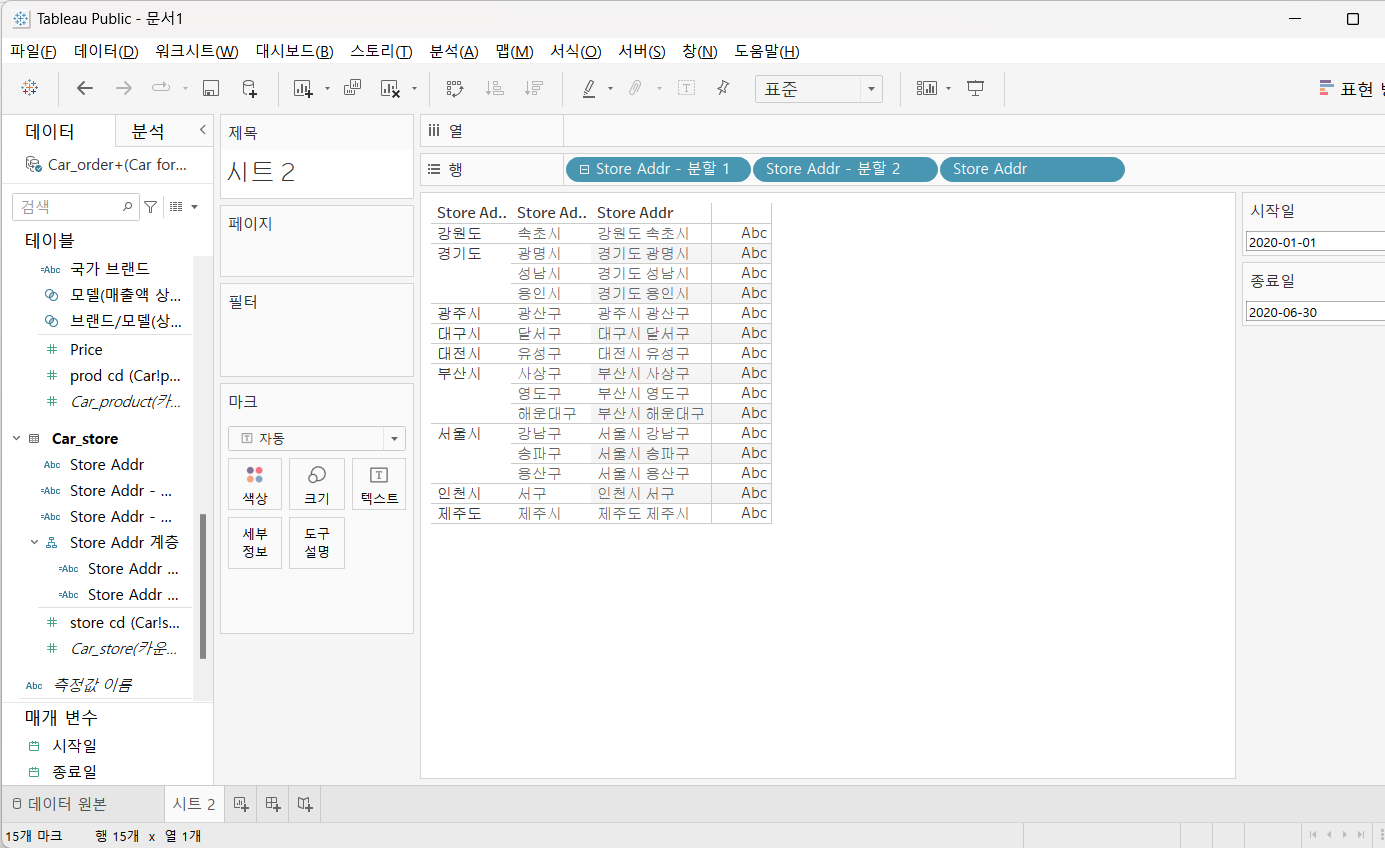
4.8) 계층
- 여러 차원 값들을 하나의 계층으로 만들 때 사용
하나의 테이블에 상위와 하위 필드가 같이 존재하는 경우에는 계층을 미리 만들어 두는 것이 좋습니다.
계층을 만들어두면 계층을 뷰에 배치할 때 + 아이콘을 만들어서 펼쳐서 보거나 전체 보기를 할 수 있도록 해줍니다
- 분할 1과 분할 2를 합쳐서 계층을 생성
2개의 필드를 선택하고 분할 2의 추가 메뉴를 눌러서 [계층] - [계층 만들기] 선택

+ 버튼 클릭시 펼침과 숨김 기능을 사용 가능
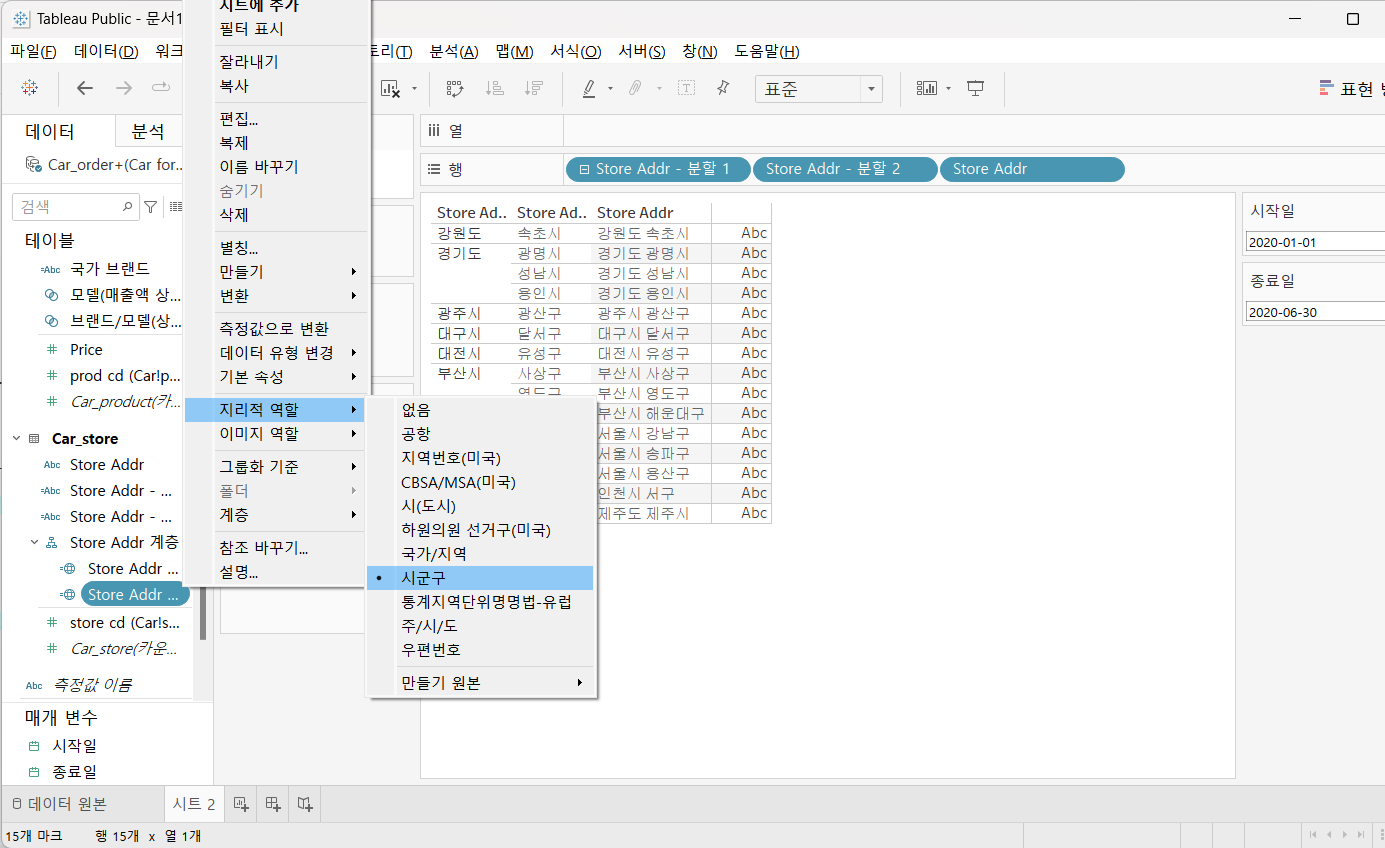
4.9) 데이터 유형 변환 및 지리적 역할
- 데이터 유형 변환 : 자료형 변환
- 지리적 역할 : 국가나 시군구 등의 기능으로 변환
- 지리적 역할 실습
[Store Addr - 분할1]을 선택하고 추가 메뉴를 클릭해 [지리적 역할] - [시/도]
[Store Addr - 분할2]을 선택하고 추가 메뉴를 클릭해 [지리적 역할] - [시/군/구]
데이터를 확인해 보면 지구본 모양의 아이콘이 추가됨
[StoreAddr 계층]을 마크 카드의 색상 및 세부 정보에 드래그
표현 형식에서 지도를 선택
크기에 데이터를 삽입하면, 점의 크기는 데이터의 크기로부터 변환됨.

파이썬에 비해서 간단히 데이터 기반 시각화가 편리함(심지어 위치 기반 까지)
4.10) 차원 및 측정 값 변환
- 차원(Factor - 범주)을 측정 값으로 변환하거나 측정 값을 차원으로 변환하는 것
- 차원인 Model을 측정 값으로 변환
Model 필드를 행으로 드래그
Model 필드를 클릭 후 [측정 값] - [카운트]를 선택하면 카운트를 반환
차원을 측정값으로 변환하는 것은 개수를 세는 것 이외에는 큰 의미가 없다.
- 일반적으로는 측정 값을 차원으로 변경하는 경우가 많음
설문조사를 하거나 데이터베이스에 데이터를 저장할 때 ENUM 스타일을 사용하지 못하므로 숫자로 변환해서 저장하는 경우가 있습니다.
숫자로 저장을 하게되면 읽어올 때 측정 값으로 읽어오는 경우가 발생하여 측정 값으로 되돌리거나 변환 작업이나 계산된 필드를 이용해서 다시 범주형으로 만드는 경우가 있습니다.
5. 뷰 편집
5.1) 서식
- 글꼴/ 맞춤/ 음영/ 테두리/ 라인을 이용해서 뷰 서식 변경 가능
- 매출액 과 평균가격을 이용해서 분산형 차트(Scatter - 분포 확인 또는 상관관계 파악 : 측정 값 2개를 가지고 생성)를 만들고 서식 변경
매출액과 평균 가격을 행과 열에 드래그
마크 카드의 세부 정보에 Brand 와 Model 필드를 드래그
뷰 영역에서 마우스 오른쪽을 클릭해서 [서식] 메뉴를 실행해서 서식 변경
워크 시트를 선택하고 수정하면 X, Y축 모두 영향을 받고 상단의 필드에서 특정 필드를 선택하면 선택한 필드만 수정됨
5.2) 축 편집
- 범위나 눈금 또는 축 제목과 눈금선을 편집
- 축을 선택하고 마우스 오른쪽 눌러서 [축 편집]을 클릭하고 설정
5.3) 추세선
- 선형 / 로그 / 지수 / 거듭 제곱/ 다항식을 활용해서 측정 값들의 추세를 표시
- 뷰에서 마우스 오른쪽을 클릭하고 추세선 -> 추세선 표시를 클릭
선형 추세선이 자동 생성
- 추세선을 선택하고 마우스 오른쪽을 누르면 [모든 추세선 편집]을 선택해서 추세선 작성 함수를 변경할 수도 있고 신뢰구간 표시 가능
신뢰구간(Confidence Interval) : 모수가 어느 범위 안에 있는 지를 확률적으로 보여주는 방법 중의 하나로 신뢰 수준을 설정해서 이 구간안에 있을 확률이 95% 나 99% 정도 된다고 설명
선형 / 로그 / 지수 / 거듭 제곱 / 다항식 형태가 있는 이유는 기본은 선형 회귀인데 선형 회귀는 회귀를 잘 설명하지 못하는 경우가 있어서 이런 경우에는 거듭제곱이나 다항식 등을 이용해서 회귀를 설명합니다.
추세선을 클릭하면 3개의 내용이 출력됩니다
첫번째 출력 내용이 회귀식
두번째 출력 내용이 R2 Score (R-squared)로 우리말로 결정 계수, 회귀 모델에서 독립변수가 종속 변수를 얼마나 잘 설명하는가를 보여주는 지표
이 값이 1에 가까울 수록 독립 변수들이 종속 변수를 잘 설명한다고 합니다.
세번째 출력 내용은 p-value로 우리말로는 유의 확률. 귀무가설이 맞다고 가정할 때 얻은 결과보다 극단적인 결과가 실제로 관측될 확률로 이 수치는 작을 수록 결과를 신뢰할 만 합니다.
어떤 회귀식을 사용해야 할 지 결정이 잘 안되는 경우에는 p-value(유의확률)가 높은 값을 선택
5.4) 주석
- 뷰에 텍스트를 출력하는 것으로 마크 / 지점 / 영역을 활용
- 차트 영역 안에서 마우스 오른쪽을 클릭해서 주석 추가를 선택하고 설정
6. 마크 카드
6.1) 색상 / 크기 / 레이블
- 색상 / 크기 / 레이블 / 세부 정보 / 도구 설명으로 되어 있는데 마크 유형에 따라 메뉴는 유동적
- 색상 / 크기 / 레이블 : 색상이나 차트의 크기 또는 차트에 표시되는 문자열
레이블 대신에 텍스트로 보이는 경우가 있습니다.
6.2) 세부 정보 / 도구 설명
- 세부 정보는 차원 내에서 세부 차원을 적용하고자 할 때 사용
행과 열에 매출액 및 Order Date 를 드래그
Order Date 를 선택하고 추가 메뉴를 이용해서 범위와 연속성을 설정(연속형 월을 선택)
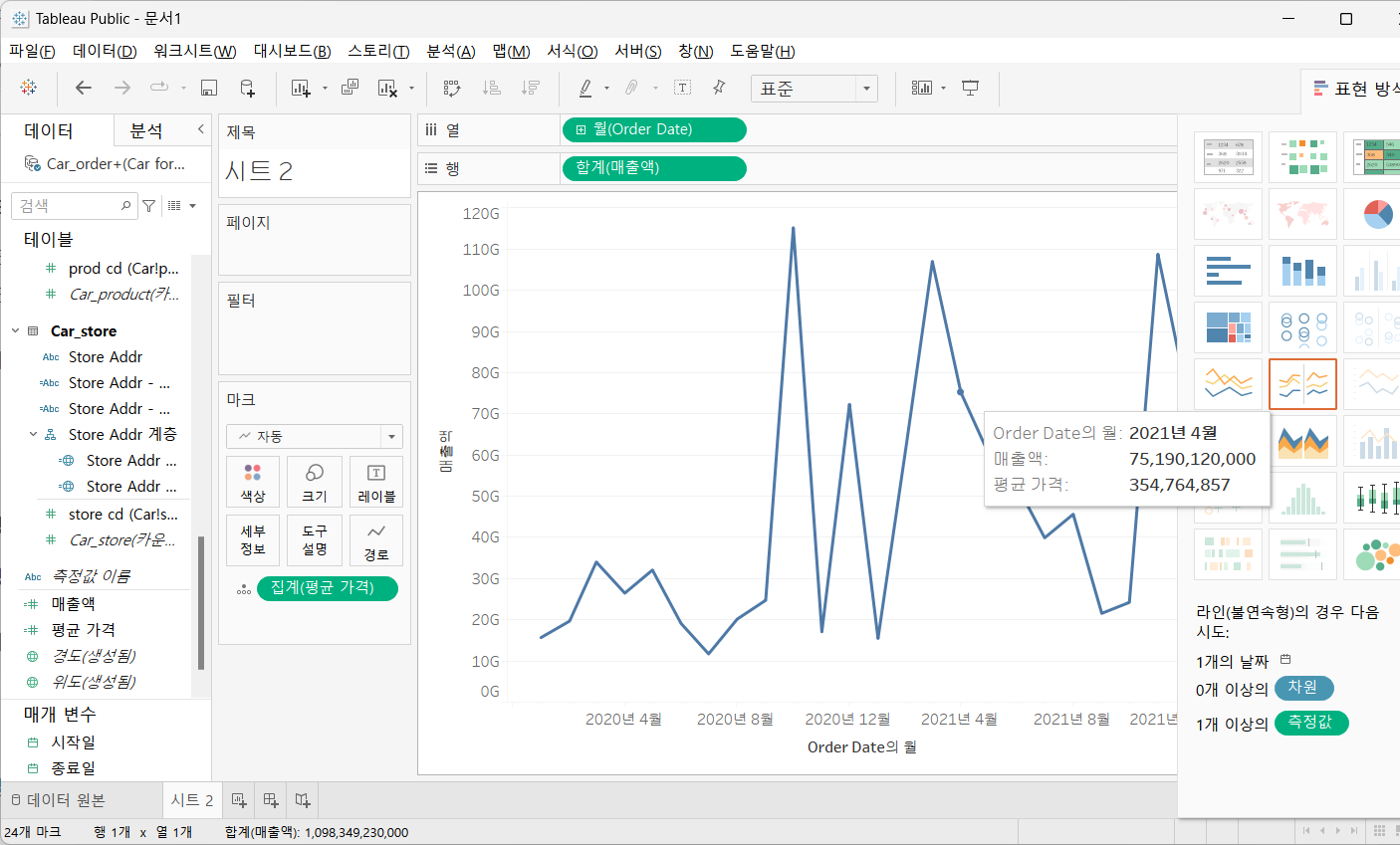
- 도구 설명은 차트에 마우스를 올려 놓을 때 보여지는 정보를 설정할 때 사용
7. 표현 방식
- 선택한 필드 값들을 기준으로 해서 적합한 뷰를 추천
빨간색 테두리로 되어 있는 것이 권장
- [Brand] 와 [매출액] 필드를 선택하고 표현 방식을 확인
8. 요약
- 뷰 안에 라인을 출력하거나 사분위수 또는 전체 합계를 출력하고자 할 때 사용하는 기능
8.1) 상수 및 평균 라인
- 상수 라인은 직접 선의 위치를 지정
- 평균 라인은 평균에 선이 그어지는 것
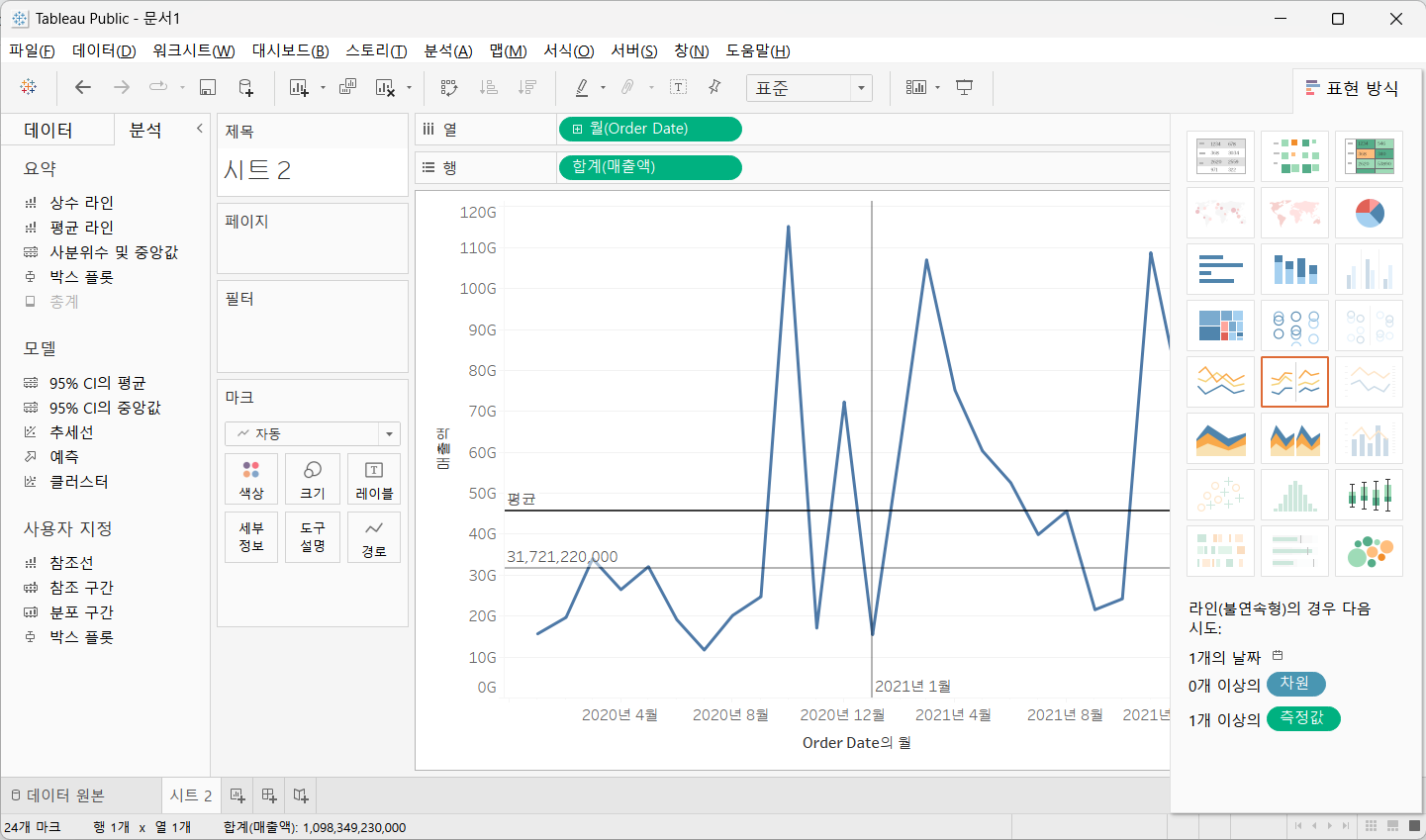
- 그래프에 상수 라인과 평균 라인 출력
행과 열에 매출액과 Order Date 를 드래그
Order Date 는 연속형 월로 선택
분석 탭에서 상수 라인을 뷰로 드래그 한 후 상수 라인을 설정할 항목을 결정하고 값을 설정

분석 탭에서 평균 라인을 뷰로 드래그 한 후 평균 라인을 설정할 항목을 결정
8.2) 사분위 수 및 중앙값
- 사분위 수는 데이터 전체를 100%로 보고 4등분 한 후 하위 25%(1사분위 수), 50%(2사분위 수, 중앙값) 75%(3사분위 수) 의 값을 사분위 수라고 함.
- 3사분위 수에서 1사분위 수 까지의 범위를 IQR 이라고 합니다.
이 범위 안에 전체 데이터의 50%가 놓이게 됨.
IQR 을 이상치 판단에 이용하는 경우가 있습니다.
- 사분위수와 중앙값 출력
행과 열에 매출액 및 Store Addr 필드 드래그
내림차순 정렬
사분위 수 및 중앙 값을 뷰에 드래그해서 테이블에 삽입

평균과 중앙값을 비교해보면, 편차가 큰 데이터임을 알 수 있다.
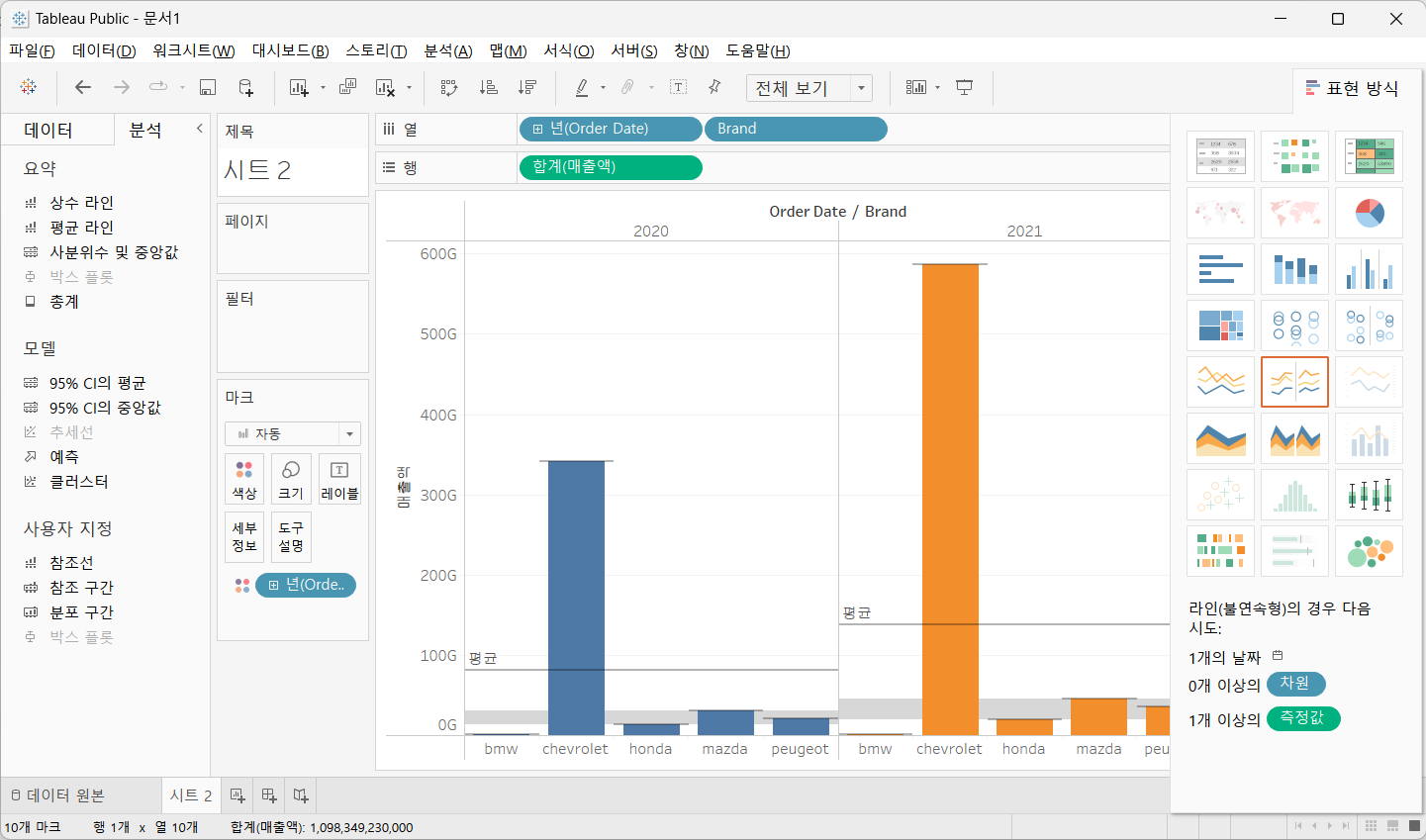
8.3) 테이블 VS 패널 VS 셀
- 분석할 항목의 범위를 설정
테이블은 전체 데이터 기준
패널과 셀이 차이가 나는 경우는 차원이 2개 이상인 경우로 첫번째 차원 기준이 패널이고 세부 차원 기준이 셀 행과 열에 매출액과 Order Date 그리고 Brand 필드가 존재하는 경우
테이블의 평균은 매출액의 평균입니다.
패널의 평균은 Order Date 가 년도 별이라면 년도 별 평균입니다.
셀의 평균은 년도별 브랜드별 평균

8.4) 박스 플롯
- 사분위 수와 중앙값 그리고 수염 정보가 박스 형태로 뷰에 표시되도록 하는 기능
- 수염은 3사분위수 * 1.5 그리고 1사분위수 * 1.5에 해당하는 부분
- Outlier를 판단하는 가장 보편적인 방법으로 수염 외부에 있는 데이터를 Outlier로 판정합니다.
실제 판단은 분석가의 몫
- 중앙 부분이 두꺼운 경우(데이터가 많은 경우) 중앙값과 별 차이가 없음에도 불구하고 Outlier가 될 수 있으므로 이상치 제거를 할 때는 분포를 확인해서 라이브러리의 도움을 받는 것이 나은지 아니면 인간이 개입을 해야되는지 판단을 해야 한다.
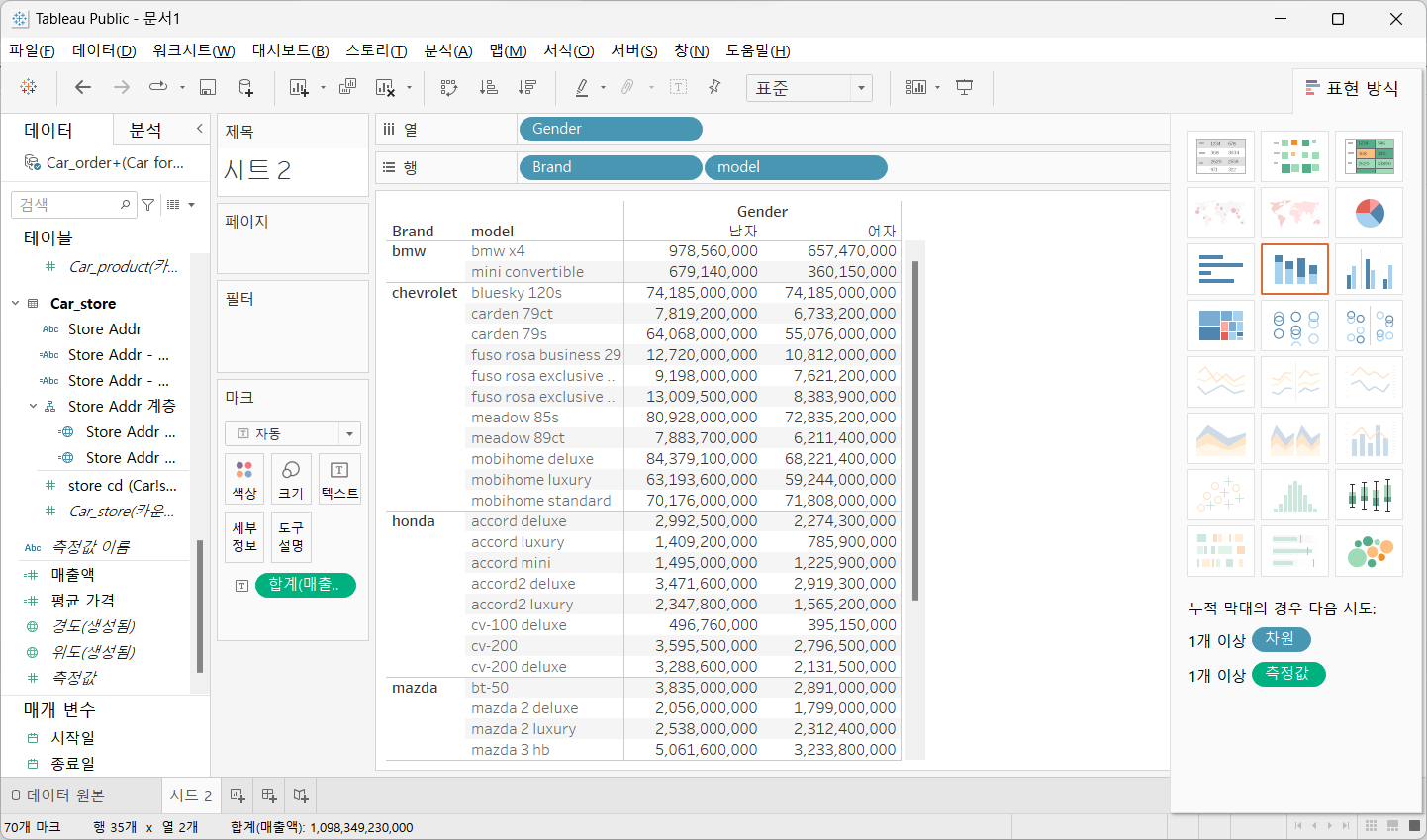
8.5) 총계
- 측정값 필드의 총계를 뷰에 표시
- 총계 출력
행과 열에 [Brand]와 [Model] 그리고 [Gender] 필드를 드래그
매출액 필드를 마크 카드의 텍스트에 드래그
사이드 바에서 [분석] 탭에서 요약에서 총계를 드래그 하면 소계, 열 총 합계, 행 총 합계 등을 출력 가능하다.
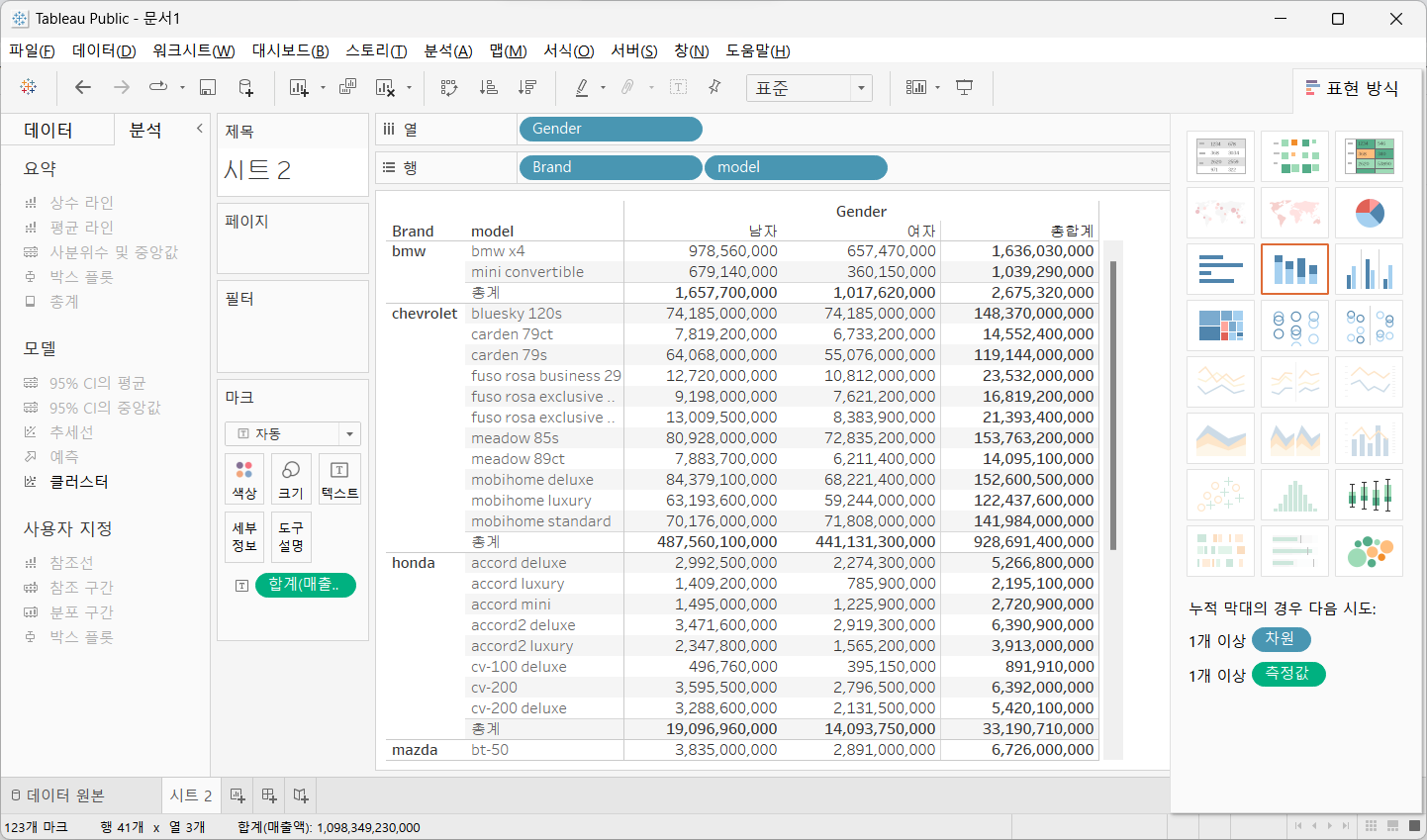
최상단의 [분석] 메뉴의 총계를 선택하면 표시 위치나 계산 값을 변경하는 것이 가능
9. 모델
- 95% CI(Confidece Interval - 신뢰수준) 의 평균, 중앙값, 추세선, 예측, 클러스터를 활용해서 뷰를 모델화
- 모델을 표시
행과 열에 Quantity 와 Order Date를 드래그
Order Date를 불연속적인 월로 변경
Quantity를 마크 카드 레이블에 드래그
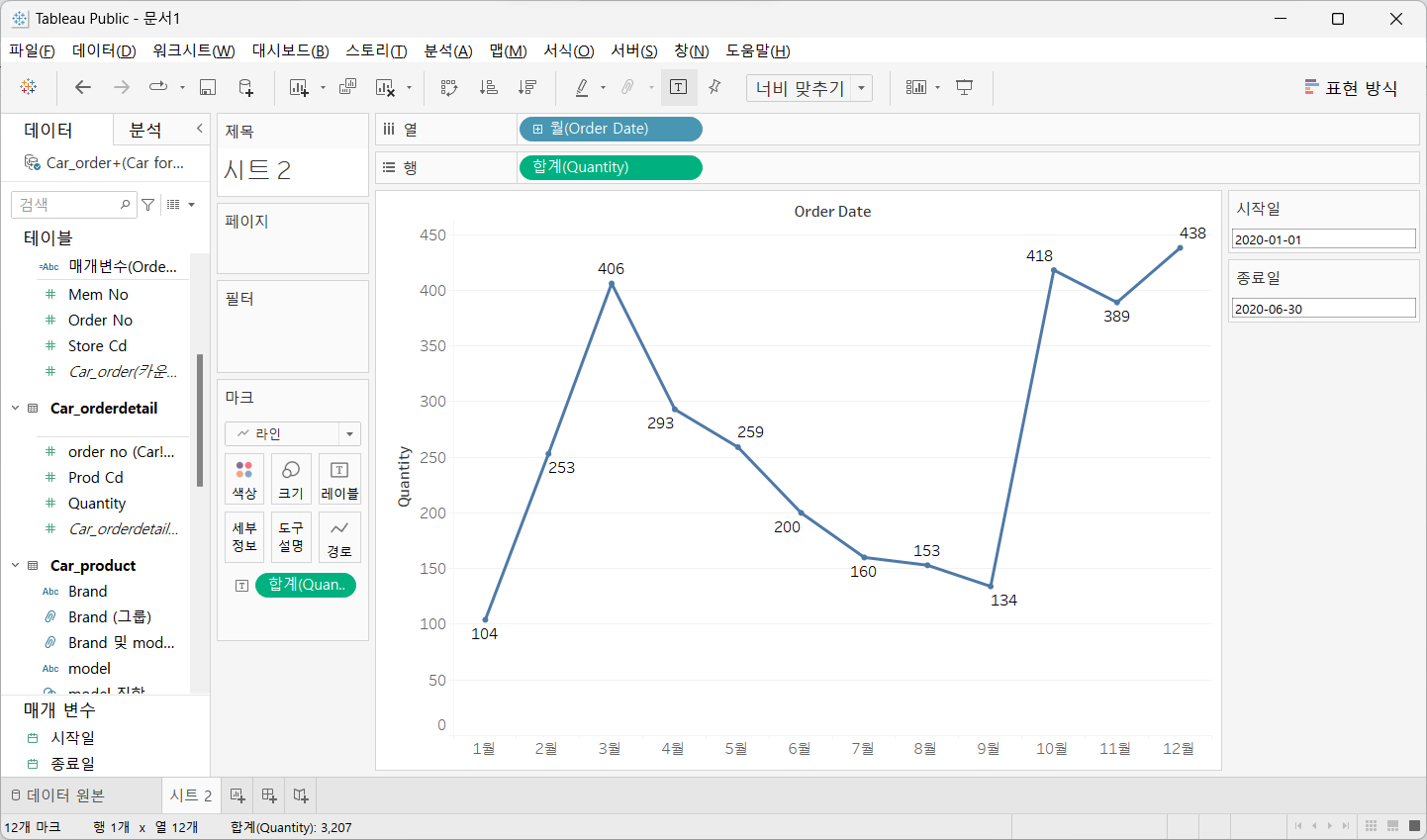
분석 탭에서 95% CI 의 평균과 중앙값을 뷰에 추가

- 추세선
2개의 측정 값의 상호 관련성을 선으로 표시 -> 2개의 측정값을 필요로함.
- 예측
날짜 필드를 활용하여 측정한 필드의 예측을 표시
행에 [Gender] 와 [매출액]을 드래그
열에 [Order Date] 필드를 드래그
[Order Date]는 연속형 분기로 변경
색상에는 [Gender]를 적용하고 레이블은 매출액을 적용

분석 탭에서 예측을 뷰로 드래그 하면 예측이 생성 됨.
라인을 선택하고 마우스 오른쪽 버튼을 클릭해서 예측 옵션을 변경할 수 있습니다.
태블로가 사용하는 방법은 지수 평활 법임.
시계열 예측 시, 주가 예측은 과거의 데이터 비중을 낮추고 최근의 데이터 비중을 높여서 예측을 합니다.
가중치를 설정해서 예측
(1 - 가중치) * 데이터1 + (1 - 가중치)^2 * 데이터2 + (1 - 가중치)^3 * 데이터3 ...
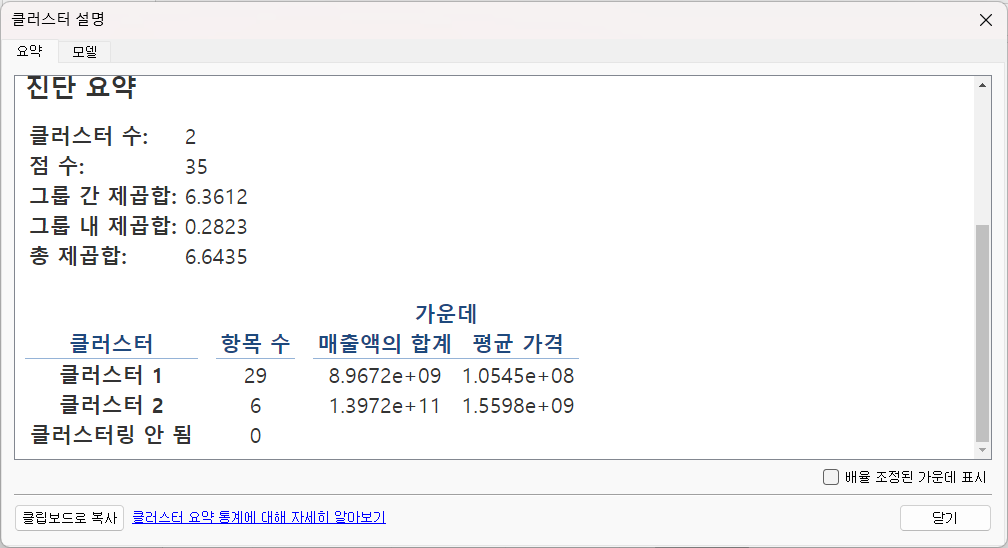
- 클러스터
그룹화 기능
그룹이 없는 데이터를 그룹화하는 작업을 클러스터링이라고 하고 이를 수행할 때 사용하는 분석 방법을 군집 분석이라고 한다.
이렇게 답이 없는 데이터를 가지고 답을 찾아가는 머신러닝을 비지도 학습이라고 합니다. <-> 지도 학습
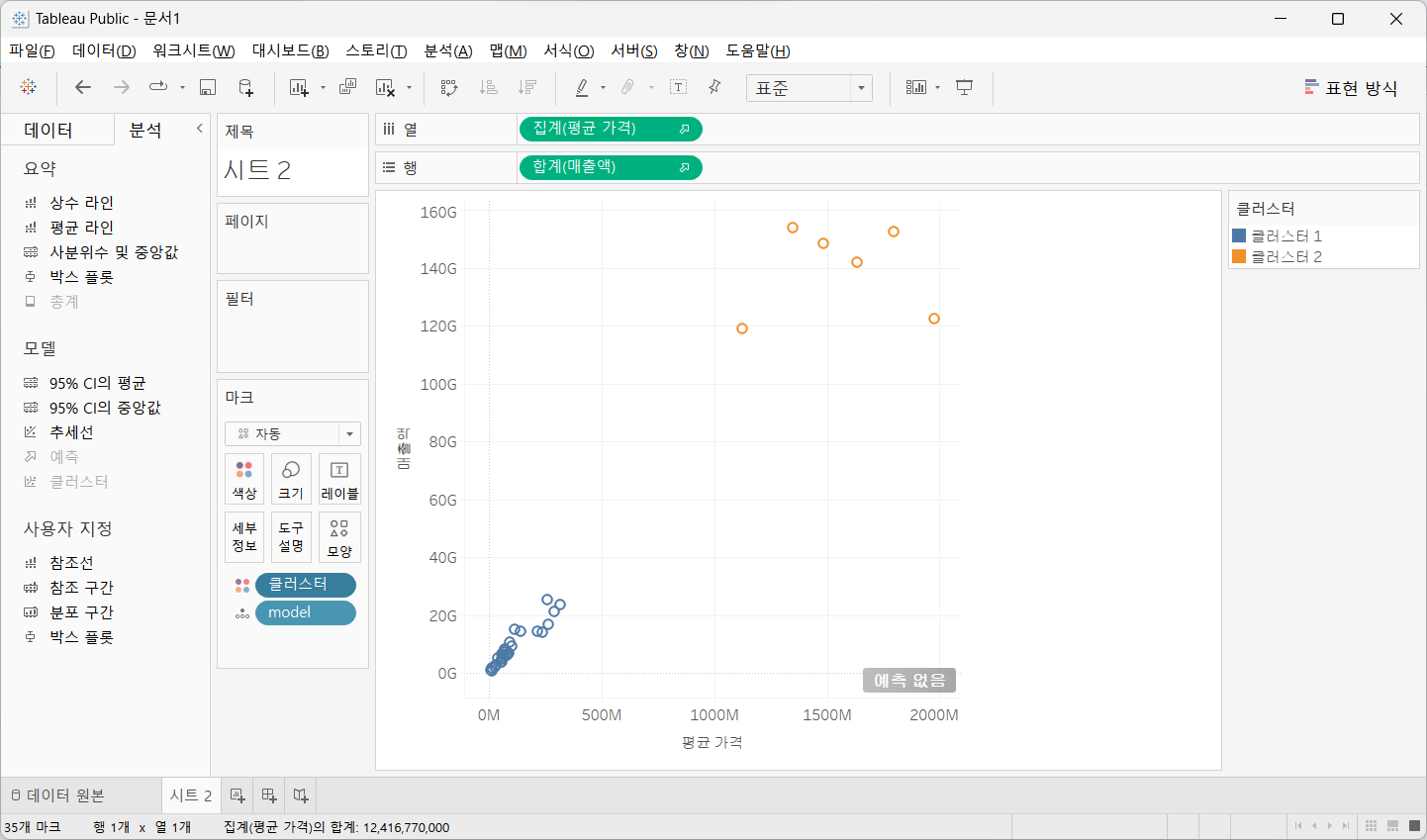
행과 열에 매출액 및 평균 가격을 드래그
마크 카드의 세부 정보에 Model 필드를 드래그
분석 탭에서 클러스터를 뷰로 드래그 하고 자동 또는 클러스터의 개수를 설정하면 됩니다.
일반적으로 자동으로 하는 것이 좋지만 목적에 따라 직접 설정해야 하는 경우도 있습니다.
10. 사용자 지정
- 분석 정보를 직접 설정하는 것
- 실습 환경
행 과 열에 매출액 및 Model(클러스터) 필드를 드래그
색상에 Model(클러스터)를 적용하고 세부정보에 Age를 적용
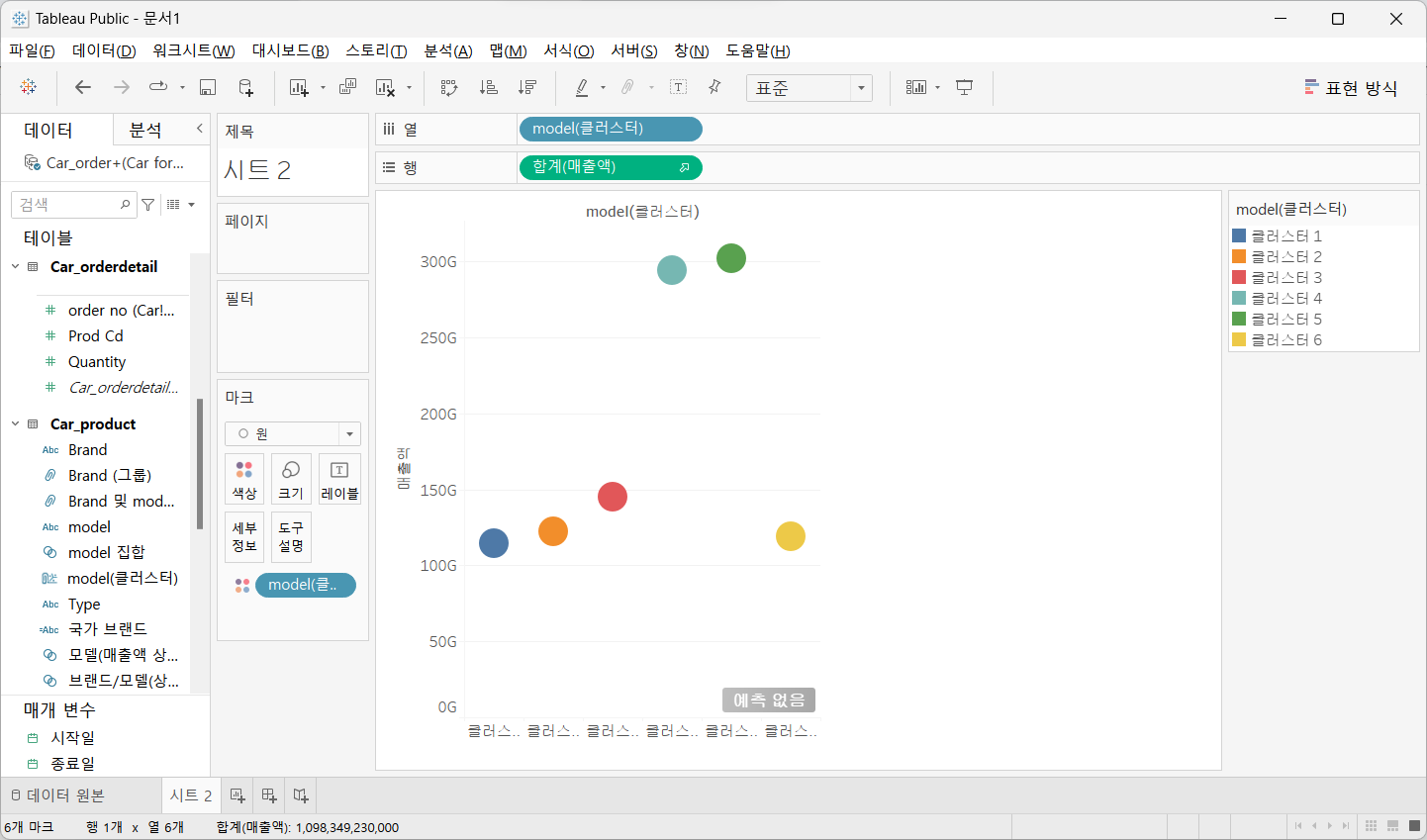

참조선을 뷰로 드래그

11. 새로운 문서를 만들고 필요한 시트를 가져오기
11.1) [파일] - [새로 만들기]를 이용해서 새로운 문서를 생성
11.2) 파일을 연결 - Car For Tableau.xls
11.3) 필요한 시트를 가져와서 Join

12. Quick Table 계산
- 데이터 시각화에 필요한 계산식(누계 / 구성 비율 / 순위 / 전년 대비 성장률 등)을 빠르게 적용할 수 있는 태블로 기능
측정 값을 가지고 하기도 하고 계산된 필드를 만들어서 적용하기도 합니다.
2023/08/03
'LG 헬로비전 DX DATA SCHOOL > Tableau' 카테고리의 다른 글
| Tableau 입문 4 (0) | 2023.08.07 |
|---|---|
| Tableau 입문 3 (0) | 2023.08.04 |
| Tableau 입문 (0) | 2023.08.02 |


